
Зміст
Розділ 1. Мова Python та її стандартна бібліотека
Програма для додавання двох чисел
Послідовність кортеж. Оператори для усіх послідовностей
Словник. Оператори для словників
Функції з довільною кількістю аргументів
Файл c:\1\package1\__init__.py:
Файл c:\1\package1\module1.py:
Файл c:\1\package1\module2.py:
Вбудовані функції для роботи з послідовностями
Атрибути класу і атрибути екземпляра
Статичні методи та методи класу
Менеджери контексту і інструкція with
inspect – перегляд об’єктів часу виконання
itertools – функції для ефективних ітерацій
re – операції з використанням регулярних виразів
decimal – дійсні числа довільної точності
time – визначення і конвертування значень часу
datetime – робота з датою і часом
calendar – робота з календарем
timeit – тривалість виконання невеликих частин коду
pickle – серіалізація об’єктів Python
shelve – збереження об’єктів Python
anydbm – універсальний доступ до DBM баз даних
sqlite3 – DB-API 2.0 інтерфейс для баз даних SQLite
csv – читання і запис файлів CSV
tarfile – читання і запис файлів архіву tar
zipfile – робота з ZIP-архівами
zlib – сумісне з gzip стиснення даних
sys – системні параметри і функції
shutil – високорівневі операції з файлами
os – створення і керування процесами
subprocess – керування підпроцесами
subprocess – міжпроцесова взаємодія
thread – створення багатьох потоків керування
threading – високорівневий інтерфейс потоків
multiprocessing – підтримка багатох процесів
multiprocessing – запуск паралельних задач
multiprocessing – міжпроцесова взаємодія
socket – низькорівневий мережевий інтерфейс
socketFileIO.py – читання і запис об’єктів Python через сокет
SocketServer – каркас для мережевих серверів
CGI-програма simple.py – генерація форми запиту
CGI-програма get_post.py - обробка запитів GET і POST
urllib2 – запити до HTTP серверів
xml.dom.minidom – мінімальна реалізація DOM
xml.etree.ElementTree – ElementTree XML API
HTMLParser – простий парсер HTML і XHTML
Tkinter – проста програма з графічним інтерфейсом
ttk.Treeview – дерево елементів
Вбудовування інтерпретатора Python у C++ програму
ctypes – виклик зовнішніх C-функцій
Розділ 2. Сторонні бібліотеки Python
IPython – інтерактивна командна оболонка
Jupyter Notebook – інтерактивні документи
Matplotlib – процедурний API pyplot
Matplotlib – об’єктно-орієнтований API
Matplotlib – додаткові параметри графіків
Matplotlib – інші типи діаграм
Matplotlib – інтерактивна побудова графіків
Bokeh – інтерактивна візуалізація
numpy.linalg – лінійна алгебра
numpy.random – генератори випадкових чисел
scipy.vectorize – векторизація функцій
scipy – похідна і первісна функції
scipy.integrate – інтегрування
scipy.integrate.odeint – звичайні диференціальні рівняння
scipy.integrate.odeint – модель польоту снаряду
scipy.integrate.odeint – модель коливань, що згасають
scipy.interpolate – інтерполяція
scipy.optimize.fsolve – розв’язування рівнянь
scipy.optimize.root – розв’язування систем рівнянь
scipy.optimize.curve_fit – регресійний аналіз
scipy.optimize.curve_fit – множинна регресія
scipy.optimize.fminbound – оптимізація функції однієї змінної з границями
scipy.optimize.fminbound – локальна оптимізація невідомої функції
scipy.optimize.fmin_l_bfgs_b – оптимізація з границями методом L-BFGS-B
scipy.optimize.differential_evolution – диференціальна еволюція
scipy.optimize.basinhopping – комбінований метод глобальної оптимізації
scipy.stats – випадкові величини
scipy.stats – підгонка кривих і перевірка статистичних гіпотез
scipy.stats.kde – ядрова оцінка густини розподілу
scipy.fftpack дискретне перетворення Фур’є
scipy.fftpack – обернене дискретне перетворення Фур’є
scikit-learn – машинне навчання
NetworkX – орієнтовані графи, алгоритми на графах
pyDatalog – логічне програмування в Python
Зв’язок з інтерпретатором Prolog
kanren – логічне програмування в Python
python-constraint – задачі виконання обмежень
PIL (Pillow) – робота з растровою графікою
PyOpenGL – прив’язка до OpenGL
pyglet – кросплатформна віконна і мультимедійна бібліотека
pythonOCC – прив’язка до геометричного ядра Open CASCADE Technology
FreeCAD – вільна САПР з Python API
Abaqus/CAE – моделювання методом скінченних елементів
OMPython – інтерфейс OpenModelica Python
xlwt – створення електронних таблиць Excel
pywin32 – інтерфейс до win32 GUI API
win32com.client – об’єкти Excel
win32com.client – об’єкти Excel з обробкою подій
win32com.client – об'єкти SOLIDWORKS
pyserial – доступ до послідовного порту
pyFirmata – комунікація комп’ютера та Arduino
concurrent.futures – запуск паралельних задач
Dask – розподілені обчислення на чистій Python
Dask.Distributed – розподілені обчислення
PyQt4 – елементи керування QtGui
PyQt4 – створення елемента керування
PyParsing – зручний синтаксичний аналіз
pymorphy2 – морфологічний аналізатор
pygments – підсвітка синтаксису
pygments – підсвітка синтаксису в Tkinter
lxml – простий і швидкий парсинг XML і HTML
Bottle – легкий WSGI веб-фреймворк
Python – це популярна високорівнева мова програмування загального призначення з акцентуванням на продуктивності розроблення. Python працює майже на усіх відомих платформах, є відкритим і вільним програмним забезпеченням, виконується шляхом інтерпретації байт-коду, підтримує кілька парадигм програмування (у тому числі об'єктно-орієнтоване), код програм компактний і легко читається (рис. 1). Мові характерні динамічна типізація, повна інтроспекція, зручні структури даних (кортежі, списки, словники, множини), велика стандартна бібліотека та велика кількість сторонніх бібліотек різноманітного призначення. Інтерпретатор Python має інтерактивний режим роботи, при якому введені з клавіатури оператори відразу ж виконуються, а результат виводиться на екран. Наприклад:
>>> a=1
>>> b=2
>>> a+b
3
>>>
Завдяки цим перевагам Python широко застосовується прикладними програмістами, зокрема інженерами і науковцями.
Основна мета цього посібника – швидке ознайомлення з основними можливостями Python для створення прикладного програмного забезпечення в галузі науки і техніки. Книга також може бути використана як довідник із Python і її пакетів. Посібник призначено для тих, хто уже володіє основами програмування якою-небудь алгоритмічною мовою. Паралельно з посібником автор рекомендує використовувати літературу [1-58] для глибшого освоєння матеріалу. Початківцям у першу чергу слід ознайомитись із книгами [16, 19, 21, 36, 56-58] для вивчення основ Python та її стандартної бібліотеки.
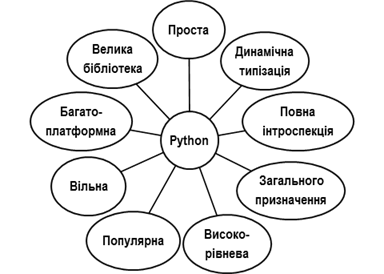
Рисунок 1 – Переваги мови Python
Автор намагався продемонструвати максимум можливостей Python на мінімальному за обсягом коді, тому більшість прикладів є дещо штучними. Приклади програм містять коментарі, що надруковані курcивом після символу #. Ці коментарі не виконуються інтерпретатором. Код програм і результати їхнього виведення надруковані моноширинним шрифтом так:
|
код програми # коментар |
текст виведення програми в консолі
Вихідний код усіх прикладів доступний на GitHub (https://github.com/vkopey/Python-for-engineers-and-scientists). Цей код розмічений спеціальним чином і містить Markdown-текст у рядкових Python-літералах ("""…"""), що дозволяє генерувати з коду документи у форматах Jupyter Notebook, HTML та MS Word 2007. Детальніше про це – https://github.com/vkopey/py2nb.
У прикладах використовується версія Python 2.7. Ви можете завантажити інтерпретатор Python 2.7 з офіційного сайту (http://python.org), або один зі сторонніх дистрибутивів Python 2.7 (Anaconda [http://www.anaconda.com], WinPython [http://winpython.github.io], Python(x,y) [http://python-xy.github.io]), які містять велику кількість пакетів. Якщо потрібного пакету немає, то його можна установити за допомогою менеджера пакетів, наприклад так:
pip install <назва пакету>
Для аналізу прикладів та розв’язування задач зручно користуватись простим і невимогливим середовищем розробки Pyzo (http://www.pyzo.org), який має підказку коду з інтерактивним показом рядка документації. З електронної версії посібника ви можете копіювати приклади, які обведені рамкою, прямо в редактор коду. Під час копіювання дотримуйтесь правил відступів у Python. Один відступ складається з чотирьох пробілів, два – з восьми і т.д. Для уникнення проблем із кодуванням символів кожна програма має починатися з рядка:
# -*- coding: utf-8 -*-
Автор буде вдячний читачам за зроблені зауваження і побажання, які можна залишити на сайті проекту в GitHub.
Розділ 1. Мова Python та її стандартна бібліотека
Найпростіша програма
Команда print виводить у консоль (стандартий потік виведення) рядкове подання об’єктів. Якщо об’єктів декілька, то їх потрібно розділити комами. Введіть в середовищі Pyzo наступний код і натисніть клавішу F5 для запуску програми.
|
print "Hello World!" # вивести на екран рядок |
Hello World!
Програма для додавання двох чисел
Функція input чекає введення Python-виразу з консолі і повертає значення цього виразу. Для введення тільки рядків використовуйте функцію raw_input [19].
|
a = input("Введіть перше
число: ") # ввести a |
Введіть
перше число: 2
Введіть друге число: a+1
5
Числові типи даних
До числових типів даних належать: цілі, дійсний, булевий і комплексний [16, 19]. У Python застосовується динамічна типізація – тип змінної визначається під час операції присвоювання. Тип змінної можна дізнатись за допомогою функції type.
|
a=16 # ціле десяткове int |
16 16 16
16 16 <type 'long'>
5.71 -3950.0
True
(1+1j)
Оператори числових типів
Приклад показує використання найбільш уживаних операторів для числових типів. У складних виразах дотримуйтесь пріоритету операторів [16, 19]. Наприклад у виразі 1+x*2 спочатку виконується множення, а потім додавання. У наступному списку пріоритет операторів зменшується зверху вниз:
· , [...] {...} `...` - створення кортежу, списку, словника, конвертація рядка
· s[i] s[i:j] s.attr f(...) - індексування, зрізи, атрибути, виклик функції
· +x -x ~x - унарні оператори
· x**y – степінь
· x*y x/y x%y - множення, ділення, остача від ділення
· x+y x-y - додавання, віднімання
· x<<y x>>y - побітовий зсув
· x&y - побітове І
· x^y - побітове XOR (виключне АБО)
· x|y - побітове АБО
· x<y x<=y x>y x>=y x==y x!=y x<>y – порівняння
· x is y x is not y – ідентичність
· x in s x not in s – членство
· not x - булеве заперечення
· x and y - булеве І
· x or y - булеве АБО
· lambda args: expr - безіменна функція
|
a=int("7") # перетворення в ціле |
7 9 3.14 (1.5+0.5j) 1.5 0.5 1.58113883008 True 1.2
-1.92222222222 1 1 4 (1, 4) False 2.92
16
16
Оператор умови if
Інструкція if виконує певні команди тоді, коли значення логічного виразу рівне True (істина) [16, 19]. Інструкція if може застосовуватись з elif та/або else. Якщо значення логічного виразу після if рівне False (не істина), то виконується інструкція elif, або, якщо її немає, виконується else. Послідовних інструкцій elif може бути довільна кількість. Зверніть увагу на відступи після символу ":", які позначають блок команд. Кожен відступ повинен складатися з пробілів (в Pyzo вони ставляться клавішею Tab) і його довжина повинна бути кратна чотирьом. Недотримання правил відступів може призвести до помилки IndentationError або до неправильної роботи програми. Для прикладу заберіть відступ у передостанньому рядку і спробуйте запустити програму. Ви отримаєте повідомлення про помилку IndentationError. Якщо видалити відступ в останньому рядку, то ви отримаєте логічну помилку – програма буде працювати неправильно.
|
x = 2 # присвоїти x 2 |
x>0, y= 2
Оператор циклу for
Інструкція for повторює виконання певних команд (тіла циклу), для кожного елемента послідовності [16, 19]. Тіло циклу позначається відступами. У наступному прикладі функція range(0,11) повертає послідовність [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]. На кожній ітерації (повторі) циклу змінній x присвоюється значення наступного елемента цієї послідовності.
|
for x in range(0,11): # для x в діапазоні [0,11) |
0 1 4 9 16 25 36 49 64 81 100
Оператор циклу while
Інструкція while повторює виконання певних команд, поки значення логічного виразу рівне True [16, 19]. У наступній програмі таким логічним виразом є x<=10. Тіло циклу позначене відступами.
|
x=0 # присвоїти x 0 |
0 1 4 9 16 25 36 49 64 81 100
Оператори break і continue
Інструкція break негайно завершує виконання циклу, а інструкція continue негайно переходить до наступної ітерації циклу [16, 19].
|
x=0 # присвоїти x 0 |
0 1 4 9 * * 36 49
Послідовність кортеж. Оператори для усіх послідовностей
Кортеж – це об’єкт-контейнер типу tuple, який містить незмінну послідовність елементів довільного типу [16, 19]. Нижче показані спільні для усіх послідовностей (tuple, list, str, unicode) оператори. До кожного елемента послідовності можна звернутись за його індексом, який вказується в квадратних дужках після назви послідовності. Індексація починається з нуля. Для прикладу a[0] – це перший елемент послідовності, a[1] - другий.
|
a = (1,2,3,4,5) # кортеж |
(1, 2, 3,
4, 5) 5 ('a', 5, 3.07) 3
1 5 (2, 4) (1, 3, 5)
3.07 a
(1, 2, 3, 4, 5, 'a', 5, 3.07)
(1, 2, 3, 4, 5, 1, 2, 3, 4, 5)
True
1 2 3 4 5
Послідовність рядок
Рядок – це об’єкт-контейнер типу str, який містить незмінну послідовність символів [16, 19, 21]. Для створення літерала рядка його потрібно взяти в апострофи, лапки або потрійні апострофи чи лапки. Кодування символів літерала рядка відповідає кодуванню символів файлу програми (тут це UTF-8). Кодування символів (ASCII, UTF-8, CP1251, CP866 та ін.) – це таблиця, у якій кожен символ кодується одним або більшою кількістю байтів.
|
s1="Рядок1" # рядок |
Рядок1 "String"2
Str
ing3 String\t4\n String5 String6\n 9
Рядок1 3.14 3.14
'\xd1' Р ядок1 '\xba'
True
x= 51.29mm
x= 16 20 10
x= five mm
hello
2
Hello
abc
020 0x10
65 A A ABC
Юнікод-рядки
Юнікод-рядок (unicode) – це послідовність символів Юнікоду [16, 19]. Для створення літерала юнікод-рядка перед лапками потрібно поставити символ u. Рядки unicodе і str підтримують однакові операції.
|
s='звичайний рядок' |
Юнікод-літерали в Python 2
В Python 2 використовувати юнікод-літерали без застосування символу u можна так:
|
from __future__ import unicode_literals |
Послідовність список
Список – це об’єкт-контейнер типу list, який містить послідовність елементів довільного типу [16, 19]. Ця послідовність може змінюватися.
|
a = [1,2,3,4,5] # список |
[1, 2, 3,
4, 5] 5 [1.0, 0.3333333333333333] 2
[1, 2, 3, 4, 5]
1 5 [2, 4] [1, 3, 5]
1 5
[1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
True
2
4
9
0 0 2 4 5 6 7
Словник. Оператори для словників
Словник (dict) – це асоціативний масив, який містить сукупність пар (ключ, значення) [16, 19]. Значеннями можуть бути об’єкти будь-якого типу, а ключами – об’єкти, які не змінюються (числа, рядки, кортежі). До кожного значення словника можна звернутись за його ключем, який вказується в квадратних дужках після назви словника. Наприклад, якщо d – словник, а 1 – ключ, то d[1] – значення за цим ключем.
|
d1={1:"Іванов",2:"Петров",3:"Коваль"} # словник |
True
Коваль 1978 Петров 1980
1980
{1: 'Male', 2: 'Male', 3: 'Male'}
Множина
Множина – це об’єкт-контейнер типу set, який містить невпорядковану сукупність елементів, які не повторюються [16, 19].
|
s1={1,1,2,3,2,5,3,1,5} # множина |
set([1, 2, 3, 5]) 4 set([8, 9, 2, 1, 7]) 5
False
1
False
False
set([1, 2, 3, 5, 7, 8, 9])
set([2])
set([3, 5])
set([1, 3, 5, 7, 8, 9])
Функції
Функція – це частина коду програми (підпрограма), до якого можна звернутись з інших місць програми [16, 19, 37]. Визначити функцію можна за допомогою інструкції def, після якої вказується назва функції і її параметри (аргументи). Код (тіло) функції записується після символу ":" і позначається відступами. Функція може повертати певне значення за допомогою інструкції return. Атрибут __doc__ містить документацію функції. Щоб викликати функцію потрібно вказати її ім’я і значення параметрів, наприклад, sum(2, 2).
|
def sum(a,b=0): #визначити функцію з
параметрами a, b |
4 4 2
Повертає суму двох чисел
Функції з довільною кількістю аргументів
Наступна функція має один обов’язковий аргумент a, довільну кількість неіменованих аргументів *b, і довільну кількість іменованих аргументів **c.
|
def f(a,*b,**c): |
1 (2, 3)
{'y': 5, 'x': 4}
1 () {'y': 5, 'x': 4, 'c': 3, 'b': 2}
lambda-функції
Невеликі анонімні функції у вигляді одного виразу можуть бути описані за допомогою ключового слова lambda [16, 19].
|
f = lambda x, y: x + y # визначення функції за
допомогою виразу |
5
Рекурсивні функції
Рекурсивна функція викликає саму себе [23]. Наприклад у коді функції bin(n) є виклик bin(n). Існує обмеження на глибину рекурсії.
|
def bin(n): # рекурсивна функція |
[1, 0, 1]
Замикання
Замикання (closure) — це функція, яка визначена в тілі іншої функції і в якій є посилання на змінні, що оголошені зовні [19, 38].
|
a=0 # глобальна змінна |
func
1 2 3
1
Обробка виняткових ситуацій
Інструкції try і except дозволяють перехоплювати і обробляти виняткові ситуації – помилки, що виникають під час виконання програми [16, 19, 37]. Якщо помилка виникає в блоці try, то керування передається тому блоку except, який відповідає типу помилки.
|
import sys # імпорт модуля sys |
-1 <type 'exceptions.AssertionError'>
0 Помилка! Ділення на нуль
0.2 <type 'exceptions.ValueError'>
inf <type 'exceptions.OverflowError'>
Файли
Файл – це інформаційний об’єкт, який містить послідовність байтів і розміщений у файловій системі на носію інформації. Усі файли є бінарними, але якщо для файлу застосовується кодування символів (ASCII, UTF-8, CP1251 або інше), то його називають текстовим. Наприклад файл із кодом Python програми (.py) є текстовим. У бінарних файлах кодування символів не застосовується. Для роботи з файлом його відкривають функцією open, яка створює файловий об’єкт, що має методи запису, читання і закриття файлу [16, 19].
|
f1=open("file1.txt", "w") # відкрити текстовий файл для
запису |
Line1
Line2
Line3
Line1
7
['Line2\n', 'Line3\n']
76 105 110 101 50 13 10 76 105 110 101 51 13 10
Модулі
Модулем є будь-який файл із вихідним кодом Python. Команда import імпортує модуль в програму, тобто код модуля виконується в окремому просторі імен і створюється об’єкт модуля, який містить об’єкти з цього простору імен [16, 19, 37]. Команда from працює аналогічно, але імпортує тільки визначені імена. Пакети містять кілька модулів. Щоб створити пакет, створіть папку з його іменем і розмістіть у ній файл __init__.py. Він виконується під час імпорту пакета. Для прикладу створіть нову папку проекту c:\1. У ній створіть файли main.py, module1.py та папку package1. У папці package1 створіть файли __init__.py, module1.py, module2.py. Виконайте модуль main.py.
Файл c:\1\main.py:
|
import sys # імпортує модуль (і
тільки 1 раз) |
module1 C:\1\module1.pyc
package1 C:\1\package1\__init__.pyc
package1.module1 C:\1\package1\module1.pyc
package1.module2 C:\1\package1\module2.pyc
a
b
__main__ C:\1\main.py
module1 doc
['a', 'f', '__builtins__', '__file__', '__package__', '__name__', '__doc__']
a_
a b c
module1 C:\1\module1.pyc
a
Файл c:\1\module1.py:
|
'''module1 doc''' # рядок документації
модуля |
Файл c:\1\package1\__init__.py:
|
# цей файл виконується під час імпорту пакета |
Файл c:\1\package1\module1.py:
|
print __name__, __file__ |
Файл c:\1\package1\module2.py:
|
print __name__, __file__ |
Математичні функції
Стандартний модуль math містить математичні функції і константи [19]. Наприклад, якщо модуль імпортується так: import math, то функції потрібно викликати так: math.sin(x).
|
from math import * # імпортувати усе з модуля
math |
0.7615941559557649
Вбудовані функції для роботи з послідовностями
Для полегшення роботи з послідовностями існують вбудовані функції [19, 21]:
• filter – фільтрує послідовність за допомогою заданої функції;
• map – застосовує функцію для кожного елемента;
• reduce – застосовує до елементів функцію двох аргументів кумулятивно зліва направо;
• zip – об’єднує послідовності в список кортежів;
• enumerate – генерує пронумеровану послідовність;
• sorted – сортує послідовність.
|
a=[1,2,3,4,5] # список |
[1, 2, 4,
5]
[1, 4, 9, 16, 25]
[2, 4, 6, 8, 10]
15
[(1, 4), (2, 5), (3, 6)]
[(0, 'a'), (1, 'b'), (2, 'c')]
[(2, 1), (1, 2), (3, 3)]
Генератори
Генератор створюється функцією, яка використовує інструкцію yield [16, 19, 37]. Застосовуються для генерування послідовностей. Виклик метода next генератора виконує цю функцію, поки не досягнуто наступної інструкції yield, повертає значення після інструкції yield і зупиняє виконання функції. Наступний виклик метода next продовжує виконання функції з наступної за yield інструкції.
|
def generator(n): # функція генератора (генерує
послідовність) |
0 1 2
0 1 2
0 0 1 1 2 2
Співпрограми
Співпрогама – це функція генератора, яка містить вираз (yield) [19, 38]. Метод send об’єкта співпрограми передає їй дані, які повертаються виразом (yield).
|
def coroutine(): # співпрограма обробляє
послідовність вхідних даних |
2 4 6
Ітератори
Ітератор – це об’єкт, який призначений для обходу елементів певного контейнера [19]. Ітератори використовуються в інструкції for. Ітератор реалізує метод next, який повертає наступний елемент контейнера, або викликає виняткову ситуацію StopIteration, якщо елементів більше немає.
|
it=iter([1,2,3]) # ітератор |
1 2 3
[1] [1, 1]
Об’єкти
Python володіє потужними об’єктно-орієнтованими можливостями. Наприклад, усі змінні, функції і класи є об’єктам і володіють атрибутами і методами. Кожен об’єкт належить до певного класу.
|
a=1 # створити змінну (об'єкт класу
int) і присвоїти їй 1 |
<type
'int'>
int
1
Класи
Об’єктно-орієнтоване програмування (ООП) основане на використанні об’єктів, які є абстрактними моделями реальних об’єктів [8, 16, 19, 26, 37, 39]. Об’єкти створюються за допомогою спеціальних типів даних – класів. Кожен клас описує множину об’єктів певного типу. Основними принципами ООП є інкапсуляція, успадкування і поліморфізм. Інкапсуляція – об’єднання даних (атрибутів) і функцій їхнього опрацювання (методів) у класі. Наприклад, у класі A об’єднано атрибут a і метод f. Ідентифікатор self використовується в класах як посилання на об’єкт цього класу. Методи об’єктів повинні мати перший аргумент self.
|
class A: # визначення класу A |
4
Клас із конструктором
Конструктор – це спеціальний метод, який має назву __init__ і викликається під час створення об’єкта [19]. Часто використовується для ініціалізації атрибутів-даних об’єкта. У прикладі також показано можливість визначення методу поза класом.
|
def f2(self,a,x=1): # визначення методу поза
класом |
4
Клас A
8
25
Успадкування і поліморфізм
Успадкування – це можливість створення похідних класів шляхом успадкування ними членів базового класу [16, 19]. Наприклад, атрибут a класу B успадкований від класу A. Поліморфізм – здатність методів з однаковою специфікацією мати різну реалізацію [19]. Наприклад, функції f класів A і B мають одну назву, але різну реалізацію.
|
class A(object): # визначення класу A,
успадкованого від object |
1 2
4
3
3
Атрибути класу і атрибути екземпляра
Важливо розрізняти атрибути класу і атрибути об’єкта цього класу [16]. Екземпляр успадковує значення атрибутів класу. Для перегляду атрибутів застосовуйте атрибут __dict__, який містить словник з атрибутами об’єкта, і функцію dir, яка повертає список атрибутів об’єкта.
|
class A(): # клас A |
{'a': 1, 'x': 2, '__module__': '__main__', '__doc__': None}
1
2
{'a': 3, 'x': 2, '__module__': '__main__', '__doc__':
None}
{'a': 4}
{'__module__': '__main__', 'b': 0, '__doc__': None}
['__doc__', '__module__', 'a', 'b', 'x']
3
5
3
Статичні методи та методи класу
Статичний метод – це функція, яка визначена в класі, але не належить класу чи екземпляру [19]. Метод класу – це метод, який належить класу, а не екземпляру [19]. Метод класу має перший аргумент cls (клас), а не self (екземпляр). Статичні методи і методи класу визначаються за допомогою декораторів @staticmethod і @classmethod.
|
class A: # визначення класу A |
3
3
2
1
Властивості
Властивість – це атрибут, який володіє методами читання, запису і знищення значення [19]. Під час присвоювання властивості значення викликається метод запису, а під час отримання значення властивості – метод читання. Властивості можна створювати в класах, які успадковані від object, за допомогою функції property або за допомогою декоратора @property.
|
class A(object): # клас A успадкований від
object |
0
Перевантаження операторів
Перевантаження (перевизначення) операторів – це можливість зміни функціонування стандартних операторів (+ , - , ==, () та ін.) для об’єктів користувача [19, 37, 38]. Для цього в класах цих об’єктів створюються реалізації відповідних методів (__add__, __sub__, __eq__, __call__ та ін.)
|
class A(object): # клас A |
<class '__main__.A'>
True
5
4
Контейнери
Контейнер – це структура даних, яка зберігає інші об’єкти в організованому вигляді [19]. Як правило клас контейнера містить методи __iter__, next, __getitem__. Приклад показує створення класу контейнера Container і його використання. Див. також модуль collections.
|
class Container(object): # клас контейнера,
успадкований від object |
1 2 3 4 5
1
2 3 4
Менеджери контексту і інструкція with
Менеджер контексту – це об’єкт, який визначає контекст (середовище) виконання інструкцій всередині блоку with [19, 38]. Містить методи __enter__ та __exit__, які автоматично викликаються на початку і вкінці блоку with. Часто використовується під час роботи з файлами. Приклад показує створення і використання класу менеджера контексту.
|
with open(__file__,'r') as f: # закриє файл автоматично |
#
with enter
1
with exit
Метакласи
Метакласи – це об’єкти, які створюють класи [16, 19, 37, 38]. Відомим метакласом є функція type. Метакласи використовуються для створення класів на етапі виконання. Нижче показані різні способи використання метакласів.
|
def cls_factory(a,fn): # функція створює новий клас
із атрибутами `a`,`fn` |
1
2
3
Декоратори
Декоратор – це функція-обгортка, яка отримує і повертає іншу функцію, метод чи клас [19, 37, 38]. Використовуються для розширення їхніх можливостей.
|
def decorator(fn): # функція-обгортка, яка отримує
і повертає fn |
y= 4
y= 4
Декоратори з аргументом
Декоратор може мати довільні аргументи [19]. У прикладі декоратор має аргумент arg, значення якого виводиться перед викликом функції, що обгортається.
|
def decorator(arg): # функція отримує аргумент і
повертає внутрішню функцію f |
y= 4
y= 4
Декоратори класу
За тим самим принципом можна обгортати класи. Приклад показує як за допомогою декоратора класу автоматично змінювати значення його атрибута __name__.
|
def decorator(arg): # функція отримує аргумент і
повертає внутрішню функцію f |
Мій клас
Інтроспекція
Інтроспекція в Python – це можливість отримати всю інформацію про структуру будь-якого об’єкта під час виконання. Найбільш відомим засобом для інтроспекції в Python є функція dir, яка повертає список імен атрибутів переданого їй об’єкта. Функція type або атрибут __class__ дозволяють отримати тип об’єкта. Функція vars або атрибут __dict__ дозволяють отримати словник із парами атрибут:значення об’єкта. Функції hasattr, getattr і setattr дозволяють відповідно перевірити наявність у об’єкта заданого атрибута, повернути його і змінити значення. Функція issubclass дає змогу визначити чи успадковується один клас від іншого, а метод __subclasses__ повертає список підкласів. Кортеж базових класів та їхню ієрархію можна отримати за допомогою атрибутів __bases__ і __mro__.
|
class A(object): # успадкований від object
клас A |
['__class__', '__delattr__', '__dict__', '__doc__', '__format__',
'__getattribute__', '__hash__', '__init__', '__module__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__',
'__str__', '__subclasshook__', '__weakref__', 'f']
['__class__', '__delattr__', '__dict__', '__doc__',
'__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__',
'__str__', '__subclasshook__', '__weakref__', 'a', 'b', 'f']
101226368
32
Клас B
Повертає суму
self.a+self.b
B
__main__
<class '__main__.B'>
B
{'a': 1, 'b': 2}
True
3
True
True
True
[<class '__main__.B'>]
(<class '__main__.A'>,)
(<class '__main__.B'>, <class
'__main__.A'>, <type 'object'>)
inspect – перегляд об’єктів часу виконання
Модуль inspect містить додаткові функції, які допомагають отримати інформацію про об’єкти часу виконання (модулі, класи, методи, функції, об’єкти трасування, кадрів виконання і коду) [5, 19].
|
import inspect |
(<class __main__.A at 0x0000000005F61D68>,)
[('__doc__', None), ('__module__', '__main__')]
None
True
False
True
ArgSpec(args=['a', 'b'], varargs='args',
keywords='kwargs', defaults=(0,))
14 21
{'a': 1, 'args': (3,), 'b': 2, 'cf': <frame object
at 0x0000000005F50930>, 'kwargs': {'x': 4}}
copy – копії об’єктів
Модуль copy призначений для створення поверхневих і глибоких копій складених об’єктів [5, 19]. Функція copy створює поверхневу копію шляхом копіювання посилань на атрибути об’єкта. Функція deepcopy створює глибоку копію шляхом рекурсивного створення окремих копій атрибутів об’єкта.
|
import copy |
<__main__.A object at 0x03653490> <__main__.B object at
0x03653810> 5
<__main__.A object at 0x03653AD0> <__main__.B
object at 0x03653810> 5
<__main__.A object at 0x03653A70> <__main__.B
object at 0x03653B10> 5
itertools – функції для ефективних ітерацій
Модуль itertools містить функції, які створюють ітератори і призначені для ефективних ітерацій по даним [5, 19]. Для економії пам’яті ітератори застосовуються з оператором for, але в прикладі вони передані функції list. Це зроблено тільки для зменшення об’єму коду прикладу.
|
from operator import add # бінарний оператор + |
[('a',
'c'), ('b', 'd')]
(0, 'a') (1, 'b') (2, 'c') (3, 'a') (4, 'b') (5, 'c')
['a', 'b', 'c', 'd']
['a', 'c']
['c', 'd']
['a', 'b']
[('a', ['a', 'a', 'a']), ('b', ['b', 'b']), ('a',
['a']), ('c', ['c'])]
['b', 'd']
[5, 7, 9]
[3, 9]
[['a', 'b', 'c'], ['a', 'b', 'c'], ['a', 'b', 'c']]
Комбінаторні генератори:
[('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')]
[('a', 'a'), ('a', 'b'), ('b', 'a'), ('b', 'b')]
[('a', 'b'), ('a', 'c'), ('b', 'a'), ('b', 'c'), ('c',
'a'), ('c', 'b')]
[('a', 'b'), ('a', 'c'), ('b', 'c')]
[('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'b'), ('b',
'c'), ('c', 'c')]
re – операції з використанням регулярних виразів
Модуль re забезпечує операції з використанням регулярних виразів [5, 19, 21]. Регулярний вираз (РВ) – це послідовність символів (шаблон), яка відповідає певній множині рядків [28]. Зазвичай використовуються для операцій пошуку чи заміни рядків. Наприклад, шаблону ‘.o’ в рядку ‘Hello World’ відповідають рядки ‘lo’ та ‘Wo’. РВ може містити звичайні (як ‘o’) і спеціальні (як ‘.’) символи. Для прикладу, спеціальний символ ‘.’ означає будь-який символ окрім символу нового рядка. Спеціальні символи сприймаються як звичайні, якщо перед ними стоїть символ ‘\’. Шаблони і рядки для пошуку можуть бути 8-бітними рядками або Юнікод-радками. Створення РВ можна суттєво спростити за допомогою таких програм як Kodos, RegexBuddy або regex101.com.
|
from __future__ import print_function |
decimal – дійсні числа довільної точності
На відміну від типу даних float, модуль decimal дозволяє точно подавати дробові десяткові значення [5, 19].
|
import sys |
False
True
sys.float_info(max=1.7976931348623157e+308, max_exp=1024,
max_10_exp=308, min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15,
mant_dig=53, epsilon=2.220446049250313e-16, radix=2, rounds=1)
inf
DecimalTuple(sign=0, digits=(1, 7, 9, 7, 6, 9, 3, 1,
3, 4, 8, 6, 2, 3, 1, 5, 7), exponent=292)
3.5953862697246314E+308
time – визначення і конвертування значень часу
Модуль time містить функції для визначення значень часу [5, 19]. Дивись також модулі datetime і calendar.
|
import time |
1.6364630143e-06
1.00987850899
1535381596.49
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=27,
tm_hour=17, tm_min=53, tm_sec=16, tm_wday=0, tm_yday=239, tm_isdst=1)
2018
* time.struct_time(tm_year=2015, tm_mon=2, tm_mday=17,
tm_hour=20, tm_min=0, tm_sec=30, tm_wday=1, tm_yday=48, tm_isdst=0)
-7200
datetime – робота з датою і часом
Модуль datetime містить класи для роботи з датою і часом – date (дата), time (час), datetime (дата і час), timedelta (період часу), tzinfo (абстрактний клас для роботи з часовими поясами) [19]. Дозволяє виконувати різноманітні математичні операції над значеннями дати і часу.
|
import datetime, time |
2018 8 27 18 5 13 543000 None
1535382313.0
26312010
1
2014-02-17 00:00:00
9 3600 0
2015-02-26 01:00:00
2015-02-26 01:00:00
True
False
2 days, 0:00:00
calendar – робота з календарем
В прикладі показані функції для виведення календаря і роботи з ним за допомогою модуля calendar [5]. За замовчуванням першим днем тиждня є понеділок, а останнім – неділя.
|
import calendar |
[datetime.date(2016, 2, 1), datetime.date(2016, 2, 2)]
0
(0, 29)
pdb – відлагоджувач Python
pdb – інтерактивний відлагоджувач (debugger) вихідного коду Python-програм, який дозволяє установлення точок зупинки, виконання в покроковому режимі, обчислення довільних Python-виразів, перегляд кадрів стеку та поставарійне відлагодження [5, 19]. Виконайте програму так:
python main.py
І введіть послідовно наступні команди відлагожувача:
n (виконувати до наступного рядка)
s (виконати рядок і зупинитись у функції,
що викликається)
a (вивести аргументи функції)
p x (вивести значення x)
!x (або так)
!x=2 (змінити значення x)
r (виконувати до виходу з функції)
c (продовжити до точки зупинки)
Відлагоджувач можна також викликати командою:
python -m pdb main.py
Щоб вийти з відлагоджувача введіть команду q. Для ознайомлення з поставарійним відлагодженням закоментуйте рядок import pdb; pdb.set_trace() і введіть у консолі команди:
python
>>> import main # тут виникне
ZeroDivisionError
>>> import pdb; pdb.pm()
x
q
>>> exit()
|
def f(x): |
timeit – тривалість виконання невеликих частин коду
Модуль timeit дозволяє просто визначати тривалість виконання невеликих частин коду [5, 19]. Для великих частин коду використовуйте модуль time. З прикладу видно, що sin(x) виконується швидше ніж math.sin(x).
|
import timeit |
0.262688315981
0.192319588135
logging – ведення журналу
В цьому модулі визначені функції і класи, які реалізують гнучку систему реєстрації подій для прикладних програм і бібліотек [16, 19]. Нижче показано найпростіший спосіб використання модуля. Приклад створює файл mylog.log з журналом подій.
|
import logging |
DEBUG
[2018-08-31 14:56:40,039] Повідомлення налагоджувача
INFO [2018-08-31 14:56:40,039] Інформаційне
повідомлення
WARNING [2018-08-31 14:56:40,039] Попередження
ERROR [2018-08-31 14:56:40,039] Помилка
CRITICAL [2018-08-31 14:56:40,039] Критичне
повідомлення
pickle – серіалізація об’єктів Python
Серіалізація – це процес перетворення якої-небудь структури даних у послідовність бітів. Часто використовується для передачі об’єктів по мережі або для збереження їх у файли. Модуль pickle реалізує алгоритми для серіалізації і десеріалізації об’єктів Python [5, 16, 19].
|
import pickle |
[1, 2, 3]
[4, 5, 6]
[7, 8, 9]
shelve – збереження об’єктів Python
Модуль shelve (полиця) призначений для збереження у постійній пам’яті Python-об’єктів (які може зберігати pickle) в об’єкті, подібному на словник [5, 19].
|
import shelve |
['1']
[1, 2, 3]
anydbm – універсальний доступ до DBM баз даних
Модуль anydbm реалізує універсальний доступ до різних DBM баз даних (БД) [5]. Для доступу до бази даних використовується подібний на словник інтерфейс. На відміну від shelve, ключі і значення словника повинні бути рядками.
|
import anydbm |
Петров
1992
Іванов 1990
sqlite3 – DB-API 2.0 інтерфейс для баз даних SQLite
SQLite – це бібліотека, яка реалізує систему керування реляційними базами даних [5, 19]. Підтримує транзакції, не потребує інсталяції, створена мовою C, швидка, не залежить від платформи. Взаємодія з базою даних відбувається мовою SQL. Модуль sqlite3 є інтерфейсом Python до SQLite.
|
import sqlite3 |
[(u'1990',)]
csv – читання і запис файлів CSV
CSV (Comma Separated Values) – це розповсюджений текстовий формат імпорту і експорту електронних таблиць і баз даних (наприклад з Excel) [5, 19]. Модуль csv реалізує класи для читання і запису табличних даних у форматі CSV.
|
import csv |
0.1 0.2
0.3
0.4 0.5 0.6
tarfile – читання і запис файлів архіву tar
Модуль tarfile дозволяє читати і записувати tar-архіви з підтримкою стиснення даних gzip або bz2 [5, 19, 27]. Приклад створює новий каталог, запаковує його в архів і розпаковує цей архів у інший каталог.
|
import tarfile, sys, os |
Каталог
0
1533569368.09
True
zipfile – робота з ZIP-архівами
Модуль zipfile містить іструменти для створення, читання і запису ZIP-архівів [5, 19]. Приклад створює новий каталог, запаковує його в архів і розпаковує цей архів у інший каталог.
|
import zipfile, os |
zlib – сумісне з gzip стиснення даних
Модуль zlib містить функції для стиснення та декомпресії даних із використанням бібліотеки zlib [5, 19].
|
import zlib |
59 12
sys – системні параметри і функції
Модуль sys містить змінні та функції, які мають відношення до інтерпретатора Python та його середовища [5, 16, 19].
|
import sys |
win32
2.7.14 |Anaconda custom (64-bit)| (default, Oct 15 2017, 03:34:40) [MSC v.1500 64 bit (AMD64)]
['E:\\Python_projects\\main.py']
24
True
hello stdout
hello console
(<type 'exceptions.IndexError'>, IndexError(), <traceback object at 0x0000000005177E88>)
os – файлова система
Модуль os забезпечує переносимий спосіб використання функціональності, пов’язаної з операційною системою [5, 19, 27]. У прикладі показані функції для роботи з файловою системою. Цю програму слід виконувати так:
python.exe main.py
|
import os,sys |
hello
True
False
True
7
('temp', 'temp.dat')
e:\python_projects
[u'temp.dat']
e:\python_projects\temp [] [u'temp.dat']
shutil – високорівневі операції з файлами
Модуль shutil містить високорівневі функції для операцій з файлами (копіювання, переміщення, архівування) [5, 19].
|
import os, shutil |
tmp/test_archive.zip.zip
os – створення і керування процесами
Процес – це об’єкт операційної системи, який описує програму, що виконується. Процес є контейнером, який містить такі ресурси як ідентифікатор процесу, образ виконуваного машинного коду програми, пам’ять, дескриптори ресурсів ОС, атрибути безпеки, стан процесора, потоки процесу. У цьому прикладі показані функції модуля os для створення і керування процесами [5, 19]. Ознайомтесь також з більш новим модулем subprocess.
|
import os |
5144
hello
0
world
status= (820, 0)
subprocess – керування підпроцесами
Модуль subprocess дозволяє створювати нові процеси, під’єднуватись до їхніх input/output/error каналів та отримувати їхні коди завершення [5, 19, 27]. Цей модуль призначений для заміни кількох старих модулів і функцій (os.system, os.spawn*, os.popen*, popen2.*, commands.*).
|
import subprocess |
0
Microsoft Windows [Version 6.1.7601]
0
1
2
3
subprocess – міжпроцесова взаємодія
main.py – модуль клієнта
Міжпроцесова взаємодія (англ. IPC) – це обмін даними між процесами. Як правило реалізується засобами ОС. До методів IPC належать: файли, неіменовані і іменовані канали, черги повідомлень, сигнали, спільна пам’ять, сокети і файли, що відображаються у пам’ять. У прикладі створюється канал між стандартними потоками введення/виведення/помилок (stdin/stdout/stderr) процесів. Цей модуль створює новий процес server.py, відсилає йому дані на stdin та отримує дані з його stdout.
|
import subprocess, pickle |
['A', 'B', 'C', 'D']
server.py – модуль сервера
Модуль отримує дані від клієнта через stdin та відсилає їх назад через stdout.
|
import pickle,sys |
thread – створення багатьох потоків керування
Потоком виконання називають частину процесу, яка може виконуватись паралельно з іншими потоками цього процесу і використовувати спільні з ними ресурси. Синхронізація потоків і процесів – це механізм, який перешкоджає одночасному їхньому зверненню до спільно використовуваних ресурсів. Модуль thread забезпечує низькорівневі (на відміну від threading) примітиви для роботи з багатьма потоками. У прикладі створюються 4 потоки, які виконують функцію f. Звернення потоків до спільного списку A синхронізовано за допомогою простого об’єкта блокування allocate_lock. Нижче показані результати роботи програми з цим об’єктом і без нього. Зауважте, що в CPython існує глобальне блокування інтерпретатора Global Interpreter Lock (GIL), яке являє собою механізм синхронізації потоків, що не дозволяє в один момент часу виконуватись більше ніж одному потоку. Тому застосовуйте модуль multiprocessing, якщо програмі потрібно задіяти для обчислень кілька процесорів. А багатопотоковість краще застосовувати у випадку багатьох одночасних задач введення-виведення.
|
import thread,time |
[0, 0, 1, 1, 2, 2, 3, 3]
[0, 1, 2, 3, 1, 3, 2, 0]
threading – високорівневий інтерфейс потоків
Цей модуль створює високорівневі інтерфейси потоків на основі низькорівневого модуля thread [5, 19]. Потоки описуються нащадком класу threading.Thread, а їхня активність – перевизначеним методом run. У прикладі створюються 4 потоки, які виконуюють код у методі run. Звернення потоків до спільного списку A синхронізовано за допомогою простого об’єкта блокування threading.Lock. Нижче показані результати роботи програми з цим об’єктом і без нього. Додатково створюється потік, який стартує через 2 секунди і додає в список A рядок ‘timer’.
|
import threading, time |
[0, 0, 1, 'timer', 1, 2, 2, 3, 3]
[0, 1, 2, 3, 2, 3, 1, 0, 'timer']
multiprocessing – підтримка багатох процесів
multiprocessing – це пакет, який підтримує створення процесів із використанням API, який подібний на API модуля threading [5, 19]. Забезпечує локальний і віддалений паралелізм, ефективно долає GIL шляхом використання підпроцесів замість потоків. У прикладі розпаралелюється задача знаходження квадратів 50 матриць 1000x1000 за допомогою класу Poll і його методу map. Зауважте, що виграш у продуктивності буде досягнуто тільки на багатопроцесорній системі. Виконайте програму послідовно в паралельному і звичайному режимах так:
python main.py
python main.py s
Для визначення продуктивності програми використано модуль timeit. У Windows можна також використати команду:
echo %time% & main.py & call echo %^time%
|
import numpy as np |
9.77497753973
15.1325679658
multiprocessing – запуск паралельних задач
Аналог прикладу concurrent.futures на основі multiprocessing. Тут функціям ProcessPoolExecutor, submit, result, map відповідають Pool, apply_async, get, map.
|
import time |
2, 4
multiprocessing – міжпроцесова взаємодія
Для обміну об’єктами між процесами можна використовувати черги (Queue), канали (Pipe), спільну пам’ять (Value, Array) [5, 19]. Клас Manager створює об’єкт, що контролює серверний процес, який зберігає об’єкти Python і дозволяє іншим процесам використовувати їх. Використання об’єктів Manager більш гнучке, ніж об’єктів спільної пам’яті, так як вони можуть підтримувати об’єкти довільних типів. Але вони більш повільні. У прикладі за допомогою Manager створюється список, у який базовий і дочірній процес паралельно додають елементи.
|
from multiprocessing import Process, Manager |
[1, 2, 3, 4]
socket – низькорівневий мережевий інтерфейс
server.py – модуль сервера
Модуль socket забезпечує доступ до API сокетів BSD [5, 19, 56]. Доступний для багатьох сучасних ОС. Найчастіше використовуються такі функції як socket (створити кінцеву точку з’єднання), bind (присвоїти сокету адресу), listen (режим очікування вхідних повідомлень), accept (прийняти з’єднання), connect (установлює з’єднання), send (надсилає дані), recv (приймає дані). Нижче наведено модуль однопотокового сервера з адресою ‘127.0.0.1’ і портом 50007. Сервер отримує дані через мережу від клієнтів та відсилає їх назад. Для виконання прикладу не потрібно наявності віддаленої машини, так як сервер і клієнт будуть виконуватись на одній машині (адреса ‘127.0.0.1’ або ‘localhost’ або ’’ означає цей комп’ютер). Виконайте цей модуль командою python server.py, а в іншому консольному вікні введіть python client.py.
|
import socket |
Server is connected to client ('127.0.0.1', 50827)
Client: A
Server is connected to client ('127.0.0.1', 50828)
Client: B
Server is connected to client ('127.0.0.1', 50829)
Client: C
Server is connected to client ('127.0.0.1', 50830)
Client: End
client.py – модуль клієнта
Надсилає дані через мережу серверу з адресою ‘127.0.0.1’ і портом 50007 та отримує їх назад.
|
import socket |
Server: A
Server: B
Server: C
Server: End
socketFileIO.py – читання і запис об’єктів Python через сокет
Нижче наведено код модуля socketFileIO.py з функціями write і read, які дозволяють відсилати чи отримувати об’єкти Python по мережі через сокети. У модулях server.py і client.py розкоментуйте виклики цих функцій і закоментуйте виклики sendall та recv.
|
import pickle |
SocketServer – каркас для мережевих серверів
Високорівневий модуль SocketServer спрощує задачі створення мережевих серверів [5, 19]. Для створення власного обробника мережевих запитів потрібно успадкувати клас BaseRequestHandler і перевизначити метод handle. У прикладі на основі SocketServer створено багатопотоковий сервер з адресою ‘127.0.0.1’ і портом 50007. Сервер отримує дані через мережу від клієнтів та відсилає їх назад. Для тестування багатопотоковості запустіть цей сервер python serverT.py і кілька клієнтів python client.py. У диспетчері завдань Windows 7 можна побачити, як змінюється кількість потоків процесу сервера.
|
import SocketServer, time |
CGI HTTP сервер
Веб-сервер — це програма, яка приймає HTTP-запити від клієнтів (зазвичай веб-браузерів) і видає їм HTTP-відповіді, як правило, з HTML-сторінкою. Протокол передачі гіпертексту HTTP описує HTTP-повідомлення, які складаються зі стартового рядка (тип повідомлення), заголовків (параметри транзакції HTTP) і необов’язкового тіла (наприклад із даними HTML). HTTP-повідомлення можна переглянути, наприклад, у браузері Firefox 61 в меню веб-розробка/мережа. Приклад HTTP-запиту типу GET до ресурсу /hello.html.
GET /hello.html
HTTP/1.1
Host: localhost
(пустий рядок)
Метод GET використовується для запиту вмісту вказаного ресурсу, а метод POST – для передачі даних вказаному ресурсу. Приклад HTTP-відповіді сервера з кодом стану 200 (виконано):
HTTP/1.0 200 OK
Content-type: text/html
(пустий рядок)
<html><body>Hello</body></html>
В прикладі створено BaseHTTPServer.HTTPServer сервер із підтримкою запитів GET, HEAD, POST і CGI-програм [5, 19]. У даному випадку усі CGI-програми повинні бути розташовані в каталозі cgi поряд із сервером. Запустіть сервер та в адресному рядку браузера введіть:
http://localhost/hello.html
|
import os, sys |

Рисунок 2 – Результати роботи сервера
CGI-програма simple.py – генерація форми запиту
CGI (Common Gateway Interface) – стандартний протокол для взаємодії програми веб-сервера із зовнішньою консольною програмою (CGI-програмою або шлюзом). Після запиту клієнта CGI-програма виконується сервером в окремому процесі, обробляє дані запиту і генерує відповідь сервера. Будь-яка CGI-програма повертає в стандартний потік виведення заголовок HTTP, пустий рядок і дані. Запустіть сервер та в адресному рядку браузера введіть:
http://localhost/cgi/simple.py
Для тестування методу GET справте нижче method="post" на method="get".
|
html="""<html><body> |
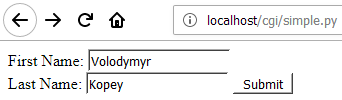
Рисунок 3 - Результати роботи CGI-програми simple.py
CGI-програма get_post.py - обробка запитів GET і POST
CGI-програма може отримати доступ до рядка запиту (даних форми) за допомогою cgi.FieldStorage. Запустіть сервер та в адресному рядку браузера введіть для тестування методів GET і POST, відповідно:
http://localhost/cgi/get_post.py?first_name=Volodymyr&last_name=Kopey
http://localhost/cgi/get_post.py`
Або, якщо форма розташована у файлах HTML, відповідно:
http://localhost/GET.html
http://localhost/POST.html
|
import cgi # модуль для обробки cgi |
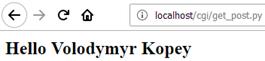
Рисунок 4 – Результати роботи CGI-програми get_post.py
WSGI сервер
WSGI (Web Server Gateway Interface) – стандарт взаємодії між Python-програмою і самим веб-сервером [19]. За стандартом WSGI веб-програма повинна бути об’єктом, що викликається, і приймати два параметра: словник змінних середовища (environ) і обробник запиту (start_response). Модуль wsgiref.simple_server реалізує простий HTTP-сервер, який виконує одну WSGI-програму. Запустіть сервер та в адресному рядку браузера введіть:
http://localhost/?name=Volodymyr
http://localhost
|
from wsgiref.simple_server import make_server |
QUERY_STRING: name=Volodymyr
REQUEST_METHOD: GET
PATH_INFO: /
HTTP_ACCEPT:
text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
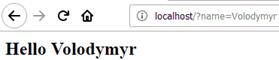
Рисунок 5 – Відповідь на запит GET
QUERY_STRING:
REQUEST_METHOD: GET
PATH_INFO: /
HTTP_ACCEPT:
text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8

Рисунок 6 – Форма для запиту POST
QUERY_STRING:
REQUEST_METHOD: POST
PATH_INFO: /
HTTP_ACCEPT: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
QUERY_STRING:
REQUEST_METHOD: GET
PATH_INFO: /pic.png
HTTP_ACCEPT: */*
Рисунок 7 – Відсилання рисунку
urllib2 – запити до HTTP серверів
urllib2 модуль містить функції і класи, які допомагають отримувати інформацію за URL переважно від HTTP серверів [5, 19, 39]. Підтримується аутентифікація, переадресація, cookie, проксі-сервера та інше.
|
import urllib, urllib2 |
http://uk.wikipedia.org/wiki/Косів
http://uk.wikipedia.org/wiki/%D0%9A%D0%BE%D1%81%D1%96%D0%B2
application/json
{
{
xml.dom.minidom – мінімальна реалізація DOM
XML – це стандарт побудови мов розмітки (мов, що використовують спеціальні анотації для розмітки тексту) ієрархічно структурованих даних. DOM (Document Object Model) – це незалежний від мови програмування програмний інтерфейс, який дозволяє створювати, читати і змінювати XML документи. DOM подає XML документи як деревовидну структуру, де кожен вузол є об’єктом, що відповідає частині документу. xml.dom.minidom – це мінімальна реалізація інтерфейсу DOM, який подібний на ті, що використовуються в інших мовах [19]. Вона простіша ніж повний DOM і суттєво менша.
|
from xml.dom import minidom |
<?xml version="1.0" ?>
<html>
<body>
<div id="1">Text</div>
</body>
</html>
xml.etree.ElementTree – ElementTree XML API
Модуль містить визначення типу Element – гнучкого контейнера, який призначений для зберігання ієрархічних структур даних у пам’яті [5, 19]. Використовується для роботи з XML і іншими деревовидними даними. Кожен елемент має такі властивості як тег, набір атрибутів, тестовий рядок, хвостовий рядок, дочірні елементи.
|
import xml.etree.ElementTree
as ET |
<root />
root
2
two
{'first': '1'}
one
two
<root><one /><two
first="1">text<two_one />text</two></root>
root one two two_one
HTMLParser – простий парсер HTML і XHTML
Цей модуль визначає клас HTMLParser, який служить як основа для синтаксичного аналізу файлів HTML і XHTML [19]. Для парсингу необхідно створити похідний від HTMLParser клас і перевизначити його методи. У Python 2.7 працює також із некоректними html. Для високопродуктивного парсингу використовуйте lxml (з ElementTree API) або Beautiful Soup.
|
from HTMLParser import HTMLParser |
Початковий
тег html
Атрибути []
Початковий тег body
Атрибути []
Дані:
Початковий тег p
Атрибути [('align', 'justify')]
Дані: Текст
Кінцевий тег: p
Дані:
Початковий тег a
Атрибути [('href', 'index.html')]
Дані: Індекс
Кінцевий тег: a
Дані:
Кінцевий тег: body
Кінцевий тег: html
Знайдені дані: Текст
Tkinter – проста програма з графічним інтерфейсом
Модуль Tkinter – це інтерфейс до Tcl/Tk (скриптової мови Tcl та її бібліотеки Tk) для мови Python [31, 32, 40]. Використовується для створення кросплатформних програм із графічним інтерфейсом (GUI). Якщо не потрібно, щоб програма показувала DOS вікно, змініть її розширення з .py на .pyw.
|
from Tkinter import * # імпортувати все з модуля
Tkinter |

Рисунок 8 – Вікно програми
Tkinter – основні класи
В прикладі показано використання основних класів Tkinter для створення програм із графічним інтерфейсом. Використано такі класи як Tk (головне вікно), Frame (фрейм або прямокутна область на екрані), Button (кнопка), Label (надпис), Entry (текстове поле), Checkbutton (прапорець), Radiobutton (перемикач), Listbox (список), Canvas (канва або область для рисування), Scale (шкала), Menu (меню), StringVar (текстова змінна), IntVar (ціла змінна), BooleanVar (булева змінна), DoubleVar (дійсна змінна).
|
from Tkinter import * |
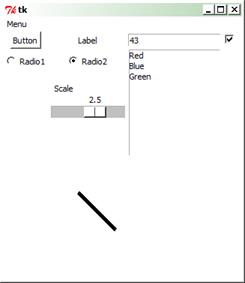
Рисунок 9 – Вікно програми
ttk.Treeview – дерево елементів
Модуль ttk містить класи, які дозволяють використання віджетів Tk із підтримкою тем оформлення. Клас ttk.Treeview дозволяє відображати ієрархічну колекцію (дерево) елементів. Кожний елемент може мати текстовий надпис, рисунок і список значень даних.
|
import Tkinter, ttk |
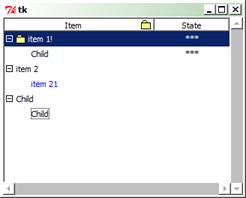
Рисунок 10 – Дерево елементів
Вбудовування інтерпретатора Python у C++ програму
Нижче показано приклад програми мовою C++, яка має можливість звернення до інтерпретатора Python [19]. Якщо використовується середовище розробки Code::Blocks 16.01 та компілятор GNU GCC Compiler, то в опціях проекту (Project build options) потрібно вказати шлях до заголовних файлів (Search directories) C:\Python27\include та під’єднати усі бібліотеки (Link libraries) з C:\Python27\libs. Якщо використовується середовище розробки Borland C++ Builder 6, то:
• Виконайте конвертацію бібліотеки: coff2omf.exe python27.lib python27_.lib.
• Скопіюйте python27_.lib у папку з проектом і переіменуйте його в python27.lib.
• Виберіть меню Project/Options…/Directories та додайте в Include path C:\Python27\include
• Додайте до проекту python27.lib та Python.h
|
#include
"Python.h" |
ctypes – виклик зовнішніх C-функцій
ctypes – це бібліотека для поступу до зовнішніх C-функцій, яка забезпечує сумісні з C типи даних і дозволяє виклик функцій з DLL або розподілюваних бібліотек Unix [14, 19]. Наступна С-функція f отримує три аргументи (змінну n та вказівники x і A) і повертає вказівник B. Зауважте, що функція змінює значення за адресами x і A.
|
#include <stdlib.h> |
Для компіляції цього коду в бібліотеку DLL застосовано команди GCC 4.9.2 (tdm-1):
mingw32-gcc.exe
-O2 -c main.c -o main.o
mingw32-gcc.exe -shared main.o -o mydll.dll -s
Тепер до бібліотеки mydll.dll можна звернутись з Python:
|
from ctypes import * |
0.0 1.0 2.0
2.0 3.0 4.0
1.0
Розширення Python мовою C++
Нижче наведено послідовність дій для створення мовою C++ Python-модуля Extest, який містить функцію fac, що повертає факторіал числа. Створення модулів розширення мовою C++ [14, 19] дозволяє вирішити проблему низької продуктивності Python.
1.Вихідний код модуля розширення мовою C++ (main.cpp):
|
int fac(int n) // рекурсивна функція, повертає
факторіал |
2.Модуль Python, який створює і установлює модуль розширення за допомогою distutils (setup.py):
|
from distutils.core import setup, Extension |
3.В командному рядку введіть (для Python 2.5 необхідне установлене MS Visual C++ 2003):
setup.py build
setup.py install
4.Перевірка роботи модуля в Python:
|
import Extest |
Розділ 2. Сторонні бібліотеки Python
IPython – інтерактивна командна оболонка
IPython 5.X (https://ipython.readthedocs.io/en/5.x/) – це командна оболонка для інтерактивних обчислень на багатьох мовах програмування, яка забезпечує інтроспекцію, мультимедіа, доступ до системної оболонки, автодоповнення коду та історію команд [27, 44, 55]. Початково розроблена для Python і є ядром більш масштабного проекту Jupyter. Широко використовується в екосистемі SciPy. Запускається командою ipython або jupyter-qtconsole.
|
Команди |
Коментар |
|
In [1]: x=1 |
Після запрошення In [1]: введіть потрібну команду. |
|
In [2]: x=x+1;x=x+2 |
Або кілька команд. |
|
In [3]: x Out[3]: 4 |
Вивести значення змінної. |
|
In [4]: x; |
Результат не виводити. |
|
In [5]: _ Out[5]: 4 |
Змінна _ містить попередній результат. |
|
In [6]: In Out[6]: ['', u'x=1', u'x=x+1;x=x+2', u'x', u'x;', u'_', u'In'] |
Змінна In містить список комірок введення. |
|
In [7]: Out Out[7]: {3: 4, 5: 4, 6: ['', u'x=1', u'x=x+1;x=x+2', u'x', u'x;', u'_', u'In', u'Out']} |
Змінна Out містить словник комірок виведення. |
|
In [8]: su<Tab> sum super |
Автодоповнення клавішею <Tab>. Використовуйте також клавіші ↑ і ↓ для пошуку команд в історії та комбінацію Ctrl-r для відкриття вікна пошуку. |
|
In [8]: sum? Docstring: sum(iterable[, start]) -> value Return the sum of an iterable or sequence of numbers ... |
Інформація про об’єкт. |
|
In [9]: sum?? |
Детальна інформація про об’єкт. |
|
In [10]: !cd e:\Anaconda2\Scripts In [11]: !!cd Out[11]: ['e:\\Anaconda2\\Scripts'] |
Для доступу до команд системної оболонки використовуйте символи "!" або "!!". |
|
In [12]: !cd <Tab> |
Автодоповнення елементів каталогу клавішею <Tab>. |
|
In [13]: files=!dir /B |
Присвоїти змінній files список файлів поточного каталогу. |
|
In [14]: file="main.py" In [15]: !dir $file |
Передати значення змінної file команді dir. |
|
In [16]: !dir {file} |
Або так. |
|
In [17]: %quickref |
Магічна команда %quickref. Магічні команди починаються з "%" (рядкові команди) або "%%" (коміркові команди) і можуть мати аргументи. |
|
In [18]: %lsmagic Out[18]: Available line magics: %alias %alias_magic %autocall ... Available cell magics: %%! %%HTML %%SVG %%bash ... |
Список усіх магічних команд. |
|
In [19]: %psearch s* set setattr ... |
Шукати усі об'єкти, що починаються з "s". |
|
In [20]: ?s* |
Або так. |
|
In [21]: %%writefile main.py ...: print sum(range(100)) ...: Writing main.py |
Створити файл із наступним вмістом: print sum(range(100)) |
|
In [22]: %run main.py 4950 |
Виконати програму в IPython. |
|
In [23]: %edit |
Викликати зовнішній текстовий редактор і виконати введений код. |
|
In [24]: %timeit sum(range(100)) 100000 loops, best of 3: 2.1 µs per loop In [25]: %time sum(range(100000)) Wall time: 8 ms Out[25]: 4999950000L |
Визначити тривалість виконання коду. |
|
In [26]: %history x=1 x=x+1;x=x+2 ... |
Вивести усі введені команди. |
|
In [27]: %history -f myhistory.py |
Зберегти усі введені команди у файл. |
|
In [28]: %pylab |
Імпортувати модулі numpy та matplotlib. |
|
In [29]: plt.plot(np.linspace(0,1)**2) Out[29]: [<matplotlib.lines.Line2D at 0x8cd2dd8>] |
Побудувати графік функції y=x2. |
Jupyter Notebook – інтерактивні документи
Jupyter Notebook – це вільна веб-програма, яка дозволяє створювати і поширювати інтерактивні документи, які містять живий програмний код, формули, візуалізацію і форматований текст (https://jupyter.org) [56]. Notebook підтримує більше 40 мов програмування, у тому числі Python. Код може створювати мультимедійне інтерактивне виведення: HTML, рисунки, відео, LaTeX і довільні MIME-типи. Jupyter Notebook широко застосовується для інтерактивних обчислень у різних галузях науки і техніки. Форматований текст в Notebook можна створювати мовою розмітки Markdown (https://daringfireball.net/projects/markdown). Це мова розмітки, яка орієнтована на легкість створення і читання документу з подальшим його перетворенням у HTML. Зокрема, текст курсивом повинен знаходитись між символами *, жирний текст – між символами **, LaTeX формула – між символами $ або $$, заголовок повинен починатись із символу # з наступним пробілом. Jupyter Notebook запускається командою jupyter-notebook. Нижче показані приклади документів Markdown та Jupyter Notebook.
|
# Заголовок Markdown текст: *курсив* **жирний** `програмний код` [Посилання](https://jupyter.org) 
>>> a=2 # програмний код >>> a**2
LaTeX формула: $a^{i\pi}_{k} + 1 = \frac{\sqrt{x+1}}{\sin x}$
|A |B |C | |--|--|--| |1 |2 |3 | |

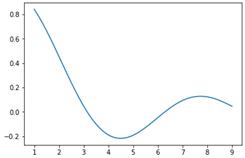

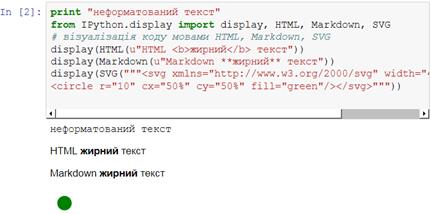
Рисунок 11 – Вигляд документа Jupyter Notebook
Matplotlib – процедурний API pyplot
Matplotlib (http://matplotlib.org) є бібліотекою для побудови різноманітних 2D діаграм у різних форматах і для різних інтерактивних середовищ [14, 25, 31, 44]. matplotlib.pyplot – це її простий у використанні інтерфейс у стилі MATLAB. Нижче показано приклад створення графіка з лінією між точками (0,0) і (1,1) за допомогою Matplotlib 2.1.1.
|
import matplotlib.pyplot as plt # імпортувати модуль
matplotlib.pyplot як plt |
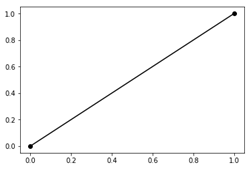
Рисунок 12 – Приклад використання matplotlib.pyplot
Matplotlib – об’єктно-орієнтований API
Об’єктно-орієнтований інтерфейс програмування Matplotlib використовує об’єкти (таких класів як figure.Figure, axes._subplots.AxesSubplot, lines.Line2D) і їхні методи для побудови графіків. Складніший у використанні ніж процедурний інтерфейс pyplot, але має більше можливостей для налаштування графіків.
|
import matplotlib.pyplot as plt |
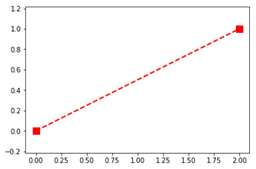
Рисунок 13 – Приклад використання об’єктно-орієнтованого API Matplotlib
Matplotlib – додаткові параметри графіків
В прикладі показно створення вкладених графіків (subplot) і використання їхніх додаткових параметрів, таких як назви і масштаб осей, заголовок, сітка, надписи. Можливо налаштувати деякі параметри за замовчування в словнику plt.rcParams.
|
import numpy as np # імпортувати модуль numpy як
np |
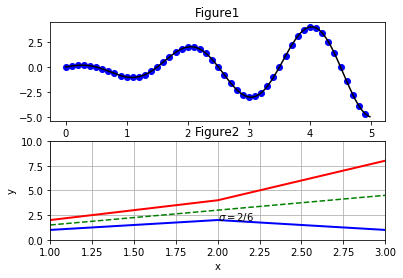
Рисунок 14 – Створення вкладених графіків
Matplotlib – інші типи діаграм
В прикладі показано створення діаграм розсіювання, гістограм, контурних діаграм та тривимірних графіків. Інші приклади використання Matplotlib для створення діаграм різного типу можна подивитись тут (http://matplotlib.org/gallery/index.html#).
|
import numpy as np |
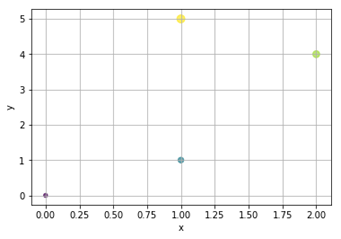
Рисунок 15 - Діаграма розсіювання
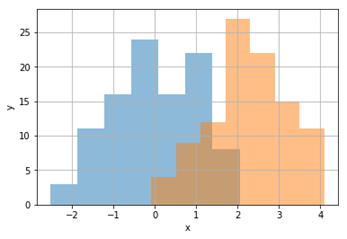
Рисунок 16 - Гістограми

Рисунок 17 - Контурна діаграма
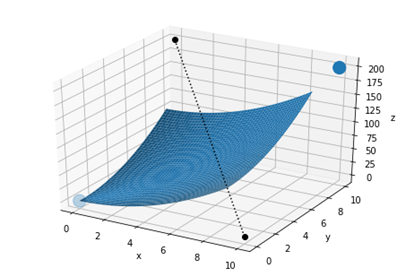
Рисунок 18 - Тривимірний графік
Matplotlib – інтерактивна побудова графіків
В прикладі графік інтерактивно перебудовується під час натиску клавіш “стрілка вгору” і “стрілка вниз”. Для цього подія key_press_event пов’язується з функцією обробки події keyPress. Цю програму бажано виконувати так: python.exe main.py
|
import matplotlib.pyplot as plt |
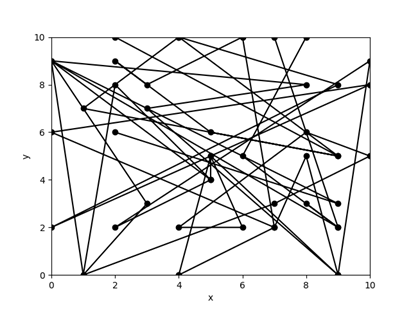
Рисунок 19 – Інтерактивний графік
Bokeh – інтерактивна візуалізація
Bokeh 0.13 (http://bokeh.pydata.org) – це бібліотека для інтерактивної і високопродуктивної візуалізації в сучасних браузерах. Використовується для створення інтерактивних програм для візуалізації даних. Цей приклад створює графік, який розташований в незалежному html-документі з javascript-сценаріями.
|
import numpy as np |
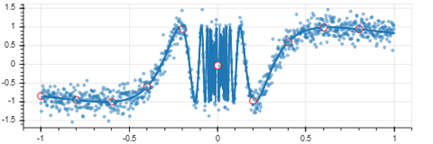
Рисунок 20 – Вигляд графіка в браузері
Bokeh – cерверна програма
За допомогою сервера застосувань Bokeh можуть бути створені клієнтські html-документи, які взаємодіють із серверною Python-програмою. Для виконання прикладу введіть у консолі:
e:/anaconda2/scripts/bokeh serve --show main.py
|
import numpy as np |
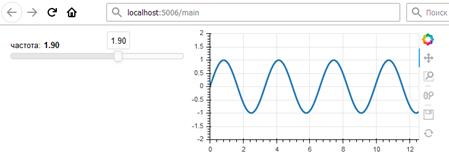
Рисунок 21 – GUI програми в браузері
numpy – робота з масивами
NumPy (http://www.numpy.org, http://scipy.org) – вільна бібліотека Python для високопродуктивних операцій з багатовимірними масивами (у тому чиcлі матрицями) [14, 25, 31, 44, 55]. NumPy є основою таких бібліотек для роботи з даними як SciPy, Matplotlib, pandas, scikit-learn та багатьох інших. Часто застосовується разом із бібліотекою SciPy, яка містить багато зручних і ефективних чисельних процедур (для інтегрування, оптимізації, інтерполяції, статистики, обробки сигналів та іншого) [14, 25, 31]. NumPy та SciPy можна розглядати як вільну альтернативу MATLAB. У прикладах використовується NumPy 1.13.3 та SciPy 0.19.1. У цьому прикладі показані базові операції з масивами: створення, властивості, доступ до частин масиву (зрізи), зміна форми, арифметичні операції, математичні функції, способи індексації, збереження у файлах, створення масивів із різнотипними елементами.
|
import numpy as np |
[0 1 2 3 4 5]
[ 0. 2.5 5. 7.5 10. ]
2 2 [1 2 3] [4 5 6] [1 4] [[1 3]]
[[2 2]
[3 4]
[5 6]]
[[2 4]
[4 6]]
[3 1 0 2]
(array([0, 1, 2], dtype=int64),)
[(1, 10., 'a') (2, 20., 'b')]
[(1, 10., 'a')]
numpy.linalg – лінійна алгебра
Модуль містить базові інструменти лінійної алгебри: для декомпозиції матриць, розрахунку власних значень, визначника, норми матриці, розв’язування систем лінійних рівнянь та інвертування матриць. У прикладі також показано відмінність типів matrix і ndarray. Модуль scipy.linalg містить функції numpy.linalg та деякі додаткові функції [14, 25], але може бути швидшим.
|
import numpy as np |
[[10 5]
[ 5 5]]
5.0
3.61803398875 [[ 0.85065081]
[ 0.52573111]]
[[ 0.00000000e+00]
[ 2.22044605e-16]]
[[ 2.]
[ 3.]]
numpy.random – генератори випадкових чисел
Модуль numpy.random містить функції для генерації випадкових чисел із різними розподілами ймовірностей.
|
import numpy as np |
[
0.8374071 0.30127402 0.74989105]
15.101728332 2.93002837893 8.58506630134
14.9962835669 2.08557855706 4.34963791765
14.9576149223 0.973514441406 0.947730367627
numpy – поліноми
В прикладі показано роботу з поліномами в NumPy: створення, отримання коренів, апроксимація поліномом [25].
|
import numpy as np |
319
[-1. 0.33333333]
[ 2.00000000e+00 -1.18450880e-15 1.17986445e-16]
scipy.vectorize – векторизація функцій
Функція scipy.vectorize визначає векторизовану функцію, яка отримує послідовність або масив numpy і повертає один або кортеж масивів numpy. Використовується для перетворення звичайних функцій в їхній векторизований варіант.
|
from scipy import vectorize |
[3 4 5]
scipy – похідна і первісна функції
В
прикладі дано функцію ![]() . Шляхом чисельного диференціювання [11] знаходиться
її похідна
. Шляхом чисельного диференціювання [11] знаходиться
її похідна ![]() . Шляхом кумулятивного інтегрування знаходиться
первісна
. Шляхом кумулятивного інтегрування знаходиться
первісна ![]() (дивись документацію функції scipy.integrate.cumtrapz).
(дивись документацію функції scipy.integrate.cumtrapz).
Похідна і
первісна можуть бути використані для пошуку екстремумів функції та для
розв’язування рівнянь. Для пошуку екстремуму y потрібно
розв’язати рівняння ![]() . А для пошуку кореня потрібно шукати екстремум
первісної Y.
. А для пошуку кореня потрібно шукати екстремум
первісної Y.
|
import numpy as np |
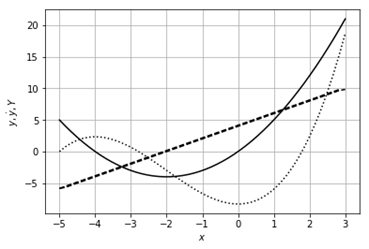
Рисунок 22 – Функція ![]() (-),
її похідна (--) і первісна (..)
(-),
її похідна (--) і первісна (..)
scipy.integrate – інтегрування
Модуль scipy.integrate містить
функції для чисельного інтегрування [11, 14, 25, 31, 53], у тому числі для
інтегрування звичайних диференціальних рівнянь. У прикладі дано функцію ![]() .
Розраховується визначений інтеграл
.
Розраховується визначений інтеграл ![]() .
.
|
import numpy as np |
(18.0, 1.9984014443252818e-13)
19.0
scipy.integrate.odeint – звичайні диференціальні рівняння
Функція scipy.integrate.odeint
розв’язує систему звичайних диференціальних рівнянь з початковою умовою чисельними
методом [11, 14, 25, 31, 45, 53]. У прикладі розв’язується просте
диференціальне рівняння з початковою умовою ![]() :
:
![]() .
.
|
from scipy.integrate import odeint |
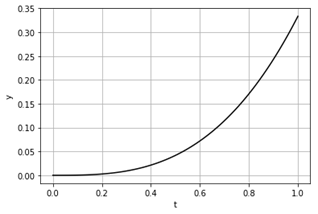
Рисунок 23 – Розв’язок диференціального рівняння
scipy.integrate.odeint – модель польоту снаряду
Модель польоту снаряду, випущеного під кутом 45 градусів до горизонту. Систему диференціальних рівнянь другого порядку
![]()
![]()
перетворимо в систему диференціальних рівнянь першого порядку
![]()
![]()
![]()
![]()
де x, y – переміщення; x’, y’ – швидкості. Початкові умови: x=0, x’=50, y=0, y’=50. Знайти функції x, x’, y, y’.
|
from scipy.integrate import odeint |
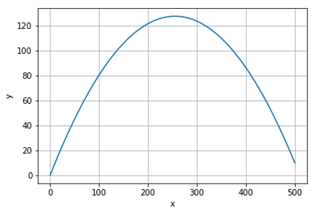
Рисунок 24 – Траєкторія переміщення y(x)
scipy.integrate.odeint – модель коливань, що згасають
Модель коливань пружини з масою m, жорсткістю j та коефіцієнтом демпфування с описується диференціальним рівнянням другого порядку
![]() .
.
Спочатку його необхідно перетворити в систему диференціальних рівнянь першого порядку
![]()
![]()
де y – переміщення, y’ – швидкість, dy’/dt – прискорення. Початкові умови: y=1, y’=0. Знайти функції y та y’.
|
from scipy.integrate import odeint |
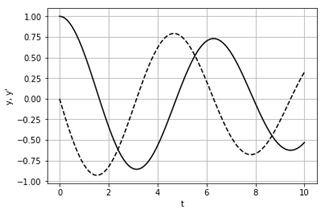
Рисунок 25 – Функції переміщення y (-) і швидкості y’ (–)
scipy.interpolate – інтерполяція
Інтерполяція – це спосіб знаходження проміжних значень величини за її відомим дискретним набором значень [9, 45, 53]. Для інтерполяції і апроксимації сплайнами застосовують функції з модуля scipy.interpolate (interp1d, UnivariateSpline, interp2d, SmoothBivariateSpline та інші) [14, 25]. Сплайн – це функція, область визначення якої розбита на частини, на кожній з яких функція є певним поліномом.
|
import numpy as np |
[0 1 2 3]
[ 1 1 4 27]
15.5 12.6458333333 9.88211768803
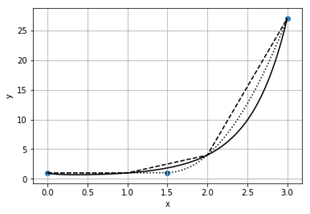
Рисунок 26 – Функція (-) та її лінійна (--) і квадратична (..) інтерполяції сплайнами
[ 1.] 0.5
scipy.optimize.fsolve – розв’язування рівнянь
Для
розв’язування нелінійного рівняння чисельним методом [9, 25, 45, 53] застосовують
функцію scipy.optimize.fsolve. Для
розв’язування систем нелінійних рівнянь див. scipy.optimize.root. У прикладі
розв’язується рівняння ![]() .
.
|
import numpy as np |
[-1.41421356 1.41421356]
scipy.optimize.root – розв’язування систем рівнянь
Для розв’язування систем нелінійних рівнянь чисельними методами [45, 53] застосовують функцію scipy.optimize.root [14]. Її необов’язковий параметр method визначає метод розв’язування системи (hybr, lm, df-sane, broyden1, broyden2, anderson, linearmixing, diagbroyden, excitingmixing, krylov). За замовчуванням використовується hybr. У прикладі розв’язується система:
![]()
![]()
|
from scipy.optimize import root |
[ 2. -4.]
scipy.optimize.curve_fit – регресійний аналіз
Регресійний аналіз (http://en.wikipedia.org/wiki/ Regression_analysis) – це статистичний метод дослідження впливу однієї або декількох незалежних змінних x на залежну змінну y [12]. Для пошуку функціональної залежності f(x), яка найкраще описує емпіричну залежність y від x, застосовують метод найменших квадратів (МНК). МНК оснований на мінімізації суми квадратів відхилень значень функції f(x) від значень y.
|
import numpy as np |
[ 1.05
0.8 ]
[[ 0.0175 -0.02625]
[-0.02625 0.06125]]
[ 0.13228757 0.24748738]
RMSE 0.295803989155
R^2: 0.969230769231
R^2: 0.969230769231
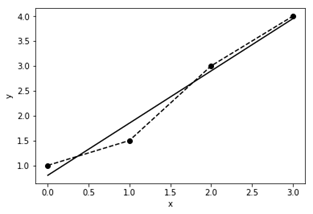
Рисунок 27 - Лінійна регресія
[ 1.05 0.8 ]
1.05 0.8
R^2: 0.969230769231
scipy.optimize.curve_fit – множинна регресія
Функція scipy.optimize.curve_fit може бути використана для апроксимації даних функцією багатьох змінних.
Таблиця 1 – Експериментальні дані – залежність y від x0 і x1
|
x1 x0 |
0 |
1 |
2 |
|
0 |
0 |
1 |
2 |
|
1 |
1 |
2 |
3 |
|
2 |
2 |
3 |
7 |
|
import numpy as np |
[-0.66666667
1.5 1.5 ]
R2= 0.678571428571
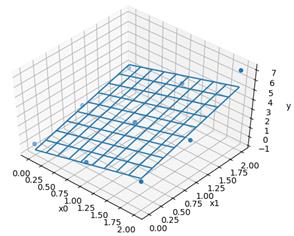
Рисунок 28 – Множинна регресія
scipy.optimize.fminbound – оптимізація функції однієї змінної з границями
В математиці оптимізацією називають задачу знаходження екстремуму (мінімуму або максимуму) функції f(x) в деякій області значень x. Оптимізація буває
• локальна – для пошуку локального екстремуму;
• глобальна – для пошуку глобального екстремуму.
Методи оптимізації поділяються на
• детерміновані;
• стохастичні;
• комбіновані.
За порядком похідної, що обчислюється, поділяються на
• прямі (обчислюються тільки значення функції);
• першого порядку (градієнтні);
• другого порядку.
Інтерфейсом для
оптимізації функції однієї змінної різними методами є minimize_scalar [14].
Розглянемо локальну оптимізацію скалярної функції (однієї змінної) ![]() методом Брента.
методом Брента.
|
import numpy as np |
argmin=
-1.75748900285
argmin= -1.75748900285
argmax= 0.730978404712
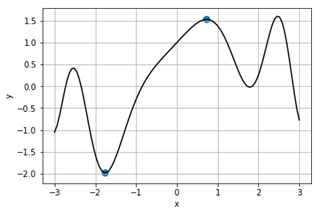
Рисунок 29 – Графік функції і знайдені локальні екстремуми
scipy.optimize.fminbound – локальна оптимізація невідомої функції
В цьому прикладі f(x) не розраховує
значення наперед відомої функції і для кожного значення x користувач
повинен ввести відповідне значення y, отримане,
наприклад, експериментом. Для прикладу ![]() , тоді на запит x=2 користувач
повинен ввести y=4. Користувач вводить y поки різниця
нового і попереднього x є великою.
, тоді на запит x=2 користувач
повинен ввести y=4. Користувач вводить y поки різниця
нового і попереднього x є великою.
|
import numpy as np |
Iteration 1 x=-0.236068 y=0.055728
Iteration 2 x=0.236068 y=0.055728
Iteration 3 x=0.527864 y=0.278640
Iteration 4 x=-0.000000 y=0.000000
Iteration 5 x=0.000003 y=0.000000
Iteration 6 x=0.000007 y=0.000000
scipy.optimize.fmin_l_bfgs_b – оптимізація з границями методом L-BFGS-B
Локальна
оптимізація векторної функції (двох змінних) популярним квазі-ньютонівським
методом L-BFGS-B, який
призначений для нелінійних задач із великою кількістю невідомих (http://en.wikipedia.org/wiki/Limited-memory_BFGS).
Інтерфейсом для оптимізації функції однієї або багатьох змінних різними
методами є minimize. У прикладі шукається мінімум функції ![]() в межах значень [-5, 5] змінних
в межах значень [-5, 5] змінних ![]() і
і ![]() .
.
|
import numpy as np |
[
-5.01107818e-09 -5.01107818e-09]
[ -5.01107818e-09 -5.01107818e-09]
Рисунок 30 – Графік функції
scipy.optimize.differential_evolution – диференціальна еволюція
Диференціальна
еволюція – це метод глобальної оптимізації функції однієї або багатьох змінних,
який відноситься до стохастичних методів оптимізації з границями. Не
використовує градієнтні методи, але потребує більшої кількості ітерацій.
Моделює такі процеси біологічної еволюції як розмноження, мутація, рекомбінація
і відбір. Доступні
різні еволюційні стратегії (http://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.differential_evolution.html). У прикладі
шукається мінімум функції ![]() в межах [1, 4.5].
в межах [1, 4.5].
|
import numpy as np |
fun: array([-4.15851032])
jac: array([ 4.79616347e-06])
message: 'Optimization terminated successfully.'
nfev: 158
nit: 9
success: True
x: array([ 4.16024526])
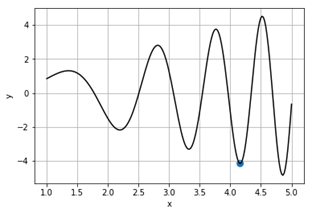
Рисунок 31 – Графік функції і знайдений мінімум у межах [1, 4.5]
scipy.optimize.basinhopping – комбінований метод глобальної оптимізації
Функція scipy.optimize.basinhopping реалізує комбінований метод глобальної багатомірної оптимізації. У кожній ітерації є етапи:
• Випадкове збурення координат.
• Локальна мінімізація.
• Прийняття або відхилення нових координати, основане на мінімізованому значенні функції.
Метод не гарантує знаходження мінімуму, оскільки алгоритм стохастичний. Алгоритм має багато параметрів, серед яких:
• x0 – початкові значення мінімумів;
• niter – кількість ітерацій алгоритму;
• T – параметр для прийняття чи відхилення критерію;
• stepsize – початковий розмір кроку для випадкових зміщень;
• minimizer_kwargs – аргументи, які передаються локальному мінімізатору. Для пришвидшення можна також передавати мінімізатору похідні функції (Якобіан, Гессіан);
• take_step – замінює функцію кроку за замовчуванням;
• accept_test – визначає тест, який використовується для прийняття або відхилення кроку;
• callback – функція, яка викликається, коли знайдено локальний мінімум.
|
import numpy as np |
[-0.19506755 -0.10000001] -1.01087618444
Loc. min. [-1.05352142 -0.09999747] -0.102110348616
True
Loc. min. [-0.19506756 -0.1 ] -1.01087618444
True
Loc. min. [-0.19506756 -0.1 ] -1.01087618444
True
Loc. min. [ 0.23417127 -0.10000023] -0.907266719691
True
Loc. min. [ 0.23417128 -0.10000001] -0.907266719691
True
[-0.19506756 -0.1 ] -1.01087618444
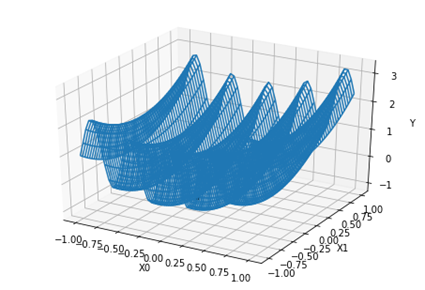
Рисунок 32 – Графік функції
scipy.stats – випадкові величини
Модуль scipy.stats містить велику кількість дискретних і неперервних розподілів імовірності і бібліотеку статистичних функцій [2, 6, 10, 14, 17]. Випадкова величина (ВВ) – це величина, значення якої є результатом випадкового явища. Розподіл ймовірностей – це закон, який описує область значень випадкової величини і імовірності їхньої появи [29]. У прикладі показані функції для роботи з ВВ.
|
import numpy as np |
14.9819184126
0.984759375625 0.969751027882
0.5
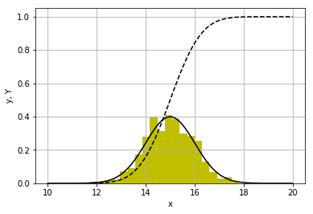
Рисунок 33 – Гістограма, функція густини ймовірностей y(x) (-)
та функція розподілу Y(x) (--)
15.0
0.997300203937
3.0
0.0
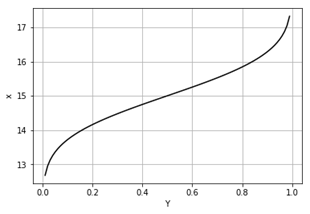
Рисунок 34 – Квантільна функція x(Y)
scipy.stats – підгонка кривих і перевірка статистичних гіпотез
Дано вибірку з N значеннями випадкової величини. Потрібно вияснити чи підлягає ця випадкова величина нормальному розподілу. Це можна зробити за допомогою:
• візуального порівняння емпіричної гістограми і кривої нормального розподілу;
• функції normaltest;
• функції kstest;
• функції chisquare.
|
import numpy as np |
6.18744549283
0.0453328770782
0.0245207935549 0.584607787303
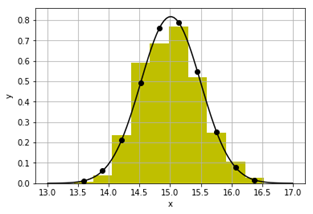
Рисунок 35 – Гістограма і функція густини розподілу
1.0
0.999957666033
Рисунок 36 – Емпіричні (--) і теоретичні (-) абсолютні частоти
16.4635646646 0.0578098854704
scipy.stats.kde – ядрова оцінка густини розподілу
Ядрова оцінка густини розподілу – це непараметричний метод оцінки функції густини випадкової величини за вибіркою [2, 17]. Задається формулою
![]()
де
![]() – значення незалежних і
однаково-розподілених випадкових величин; h – параметр згладжування; K
– статистичне ядро – симетрична, але не обов’язково додатна функція з
інтегралом рівним одиниці. У прикладі використовується Гаусове ядро:
– значення незалежних і
однаково-розподілених випадкових величин; h – параметр згладжування; K
– статистичне ядро – симетрична, але не обов’язково додатна функція з
інтегралом рівним одиниці. У прикладі використовується Гаусове ядро:
![]()
|
import numpy as np |
Рисунок 37 – Ядрова оцінка густини розподілу
scipy.fftpack дискретне перетворення Фур’є
Перетворення Фур’є — інтегральне перетворення однієї комплекснозначної функції дійсної змінної на іншу [7, 11, 14, 25]. Розкладає функцію на осциляторні функції, тобто подає сигнал у вигляді суми гармонічних коливань. Використовується для розрахунку спектра частот сигналів, які змінні у часі. Для дискретних функцій застосовують дискретне перетворення Фур’є. Модуль scipy.fftpack використовує швидкі алгоритми прямого і оберненого дискретного перетворення Фур’є (FFT).
|
import numpy as np |
Рисунок 38 – Сигнал
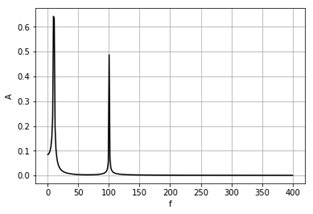
Рисунок 39 – Амплітудно-частотна характеристика сигналу
scipy.fftpack – обернене дискретне перетворення Фур’є
Обернене дискретне перетворення Фур’є повертає сигнал за спектром його частот. У прикладі показано застосування прямого і оберненого дискретного перетворення Фур’є для частотного фільтрування сигналу.
|
import numpy as np |
Рисунок 40 – Початковий і відфільтрований сигнал
Рисунок 41 – Спектр початкового і відфільтрованого сигналу
scipy.cluster – кластеризація
Кластеризація (кластерний аналіз) – задача розбиття множини об’єктів на групи (кластери) подібних об’єктів [43]. У прикладі показана кластеризація методом k-середніх, який оснований на мінімізації сумарного квадратичного відхилення точок кластерів від центрів цих кластерів. Спробуйте також потужній алгоритм кластеризації даних із наявністю шуму sklearn.cluster.DBSCAN [43].
|
import numpy |
Рисунок 42 – Результати кластеризації
pandas – аналіз даних
pandas (http://pandas.pydata.org) – бібліотека, яка базується на NumPy і містить високопродуктивні та зручні у використанні структури даних та інструменти обробки і аналізу даних [4, 44, 55]. За функціональністю pandas подібна на табличний процесор Excel. Основними структурами даних є Series (одновимірний масив ndarray з мітками осі) та DataFrame (таблиця з мітками осей (рядків і стовпців)). Приклад описує основні можливості pandas 0.20.3.
|
import numpy as np |
X1 X2
0 0 12.0
1 2 12.0
2 2 NaN
3 3 20.0
4 9 31.0
X1 int64
X2 float64
dtype: object
0 0
1 2
2 2
3 3
4 9
Name: X1, dtype: int64
[0 2 3 9]
0 0
1 2
2 2
3 3
4 9
Name: X1, dtype: int64
X1 X2
0 0 12.0
[0 2 2 3 9]
0 13.000000
1 13.165525
2 NaN
3 21.223748
4 33.280025
Name: X3, dtype: float64
X1 X2 X3
X1
0 0 12.0 12.000000
2 2 12.0 12.165525
3 3 20.0 20.223748
9 9 31.0 32.280025
X2 NaN 12.0 20.0 31.0
X1
0 NaN 12.000000 NaN NaN
2 NaN 12.165525 NaN NaN
3 NaN NaN 20.223748 NaN
9 NaN NaN NaN 32.280025
0 X1 0.000000
X2 12.000000
X3 12.000000
1 X1 2.000000
X2 12.000000
X3 12.165525
2 X1 2.000000
3 X1 3.000000
X2 20.000000
X3 20.223748
4 X1 9.000000
X2 31.000000
X3 32.280025
dtype: float64
X2 12.0 20.0 31.0
X1
0 1 0 0
2 1 0 0
3 0 1 0
9 0 0 1
X1 X2 X3
count 5.000000 4.000000 4.000000
mean 3.200000 18.750000 19.167325
std 3.420526 8.995369 9.547333
min 0.000000 12.000000 12.000000
25% 2.000000 12.000000 12.124144
50% 2.000000 16.000000 16.194637
75% 3.000000 22.750000 23.237818
max 9.000000 31.000000 32.280025
X1 X2 X3
X1 11.700000 33.500000 35.726658
X2 33.500000 80.916667 85.864232
X3 35.726658 85.864232 91.151559
X1 X2 X3
X1 1.000000 0.961568 0.966195
X2 0.961568 1.000000 0.999796
X3 0.966195 0.999796 1.000000
scikit-learn – машинне навчання
Бібліотека scikit-learn (http://scikit-learn.org) містить зручні для використання алгоритми машинного навчання з учителем (регресія, класифікація) і без учителя (кластеризація, зменшення розмірності), а також засоби для підготовки даних і вибору найкращої моделі даних [3, 10, 14, 20, 35, 43, 44, 46]. У прикладі за допомогою scikit-learn 0.19.1 розв’язується задача бінарної класифікації [41, 50]. Необхідно навчити класифікатор RandomForestClassifier [29] розпізнавати класи y нових даних x1, x2. Для цього модель навчається на даних для навчання. Тестові дані використовуються для перевірки правильності роботи моделі на нових даних. Як видно, ця модель правильно визначає класи 100% тестових даних.
Але така однократна процедура не є надійною. Для надійної перевірки правильності в прикладі застосовується 3-х блокова перехресна перевірка моделі. Вона виконується шляхом поділу усіх даних на 3 частини (xy1, xy2, xy3). Далі для кожної частини функція cross_val_score виконує навчання моделі і розрахунок правильності на незадіяних для навчання частинах. Тепер середнє значення правильності – 85 %.
Окремою проблемою є визначення оптимальних значень параметрів моделі n_estimators і max_depth. Якщо кількість їхніх варіантів не велика, то можна виконати цю програму для різних значень і подивитись, у якому випадку правильність найвища.
|
import numpy as np |
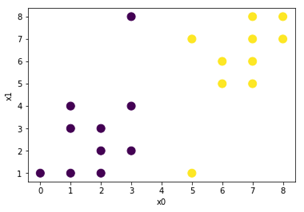
Рисунок 43 – Два класи даних
[1 0 0 0 1 0 0 0 1
1]
[1 0 0 0 1 0 0 0 1 1]
1.0
[ 0.875 1. 0.66666667] 0.847222222222
NetworkX – графи
Граф – це абстрактний математичний об’єкт, який являє собою множину вершин і ребер, які з’єднують пари вершин [1]. NetworkX (http://networkx.github.io) – це пакет для створення, маніпуляції і вивчення структури, динаміки і функціонування комплексних графів [59]. У прикладі показані основи створення і використання неорієнтованих графів за допомогою NetworkX 2.0.
|
import networkx as nx |
5 5
nodes ['A', 1, 2, 3, 4]
edges [('A', 2), (1, 2), (2, 3), (2, 4), (3, 4)]
adj {'A': {2: {}}, 1: {2: {}}, 2: {'A': {}, 1: {}, 3: {},
4: {}}, 3: {2: {}, 4: {}}, 4: {2: {}, 3: {}}}
degree [('A', 1), (1, 1), (2, 4), (3, 2), (4, 2)]
[('A', 2), (2, 1), (2, 3), (2, 4), (3, 4)]
{'A': {}, 1: {}, 3: {}, 4: {}}
[('A', 1), (2, 4), (3, 2)]
{'a': 'val1'}
{'color': 'blue', 'weight': 4}
Сусіди вузла A
2 {}
Сусіди вузла 1
2 {'color': 'blue', 'weight': 4}
Сусіди вузла 2
A {}
1 {'color': 'blue', 'weight': 4}
3 {}
4 {}
Сусіди вузла 3
2 {}
4 {}
Сусіди вузла 4
2 {}
3 {}
Рисунок 44 – Візуалізація графа
NetworkX – орієнтовані графи, алгоритми на графах
Ребра графа, які мають напрямок, називають дугами. Неорієнтований граф містить тільки ребра, а орієнтований граф містить тільки дуги. У NetworkX орієнтовані графи створюються за допомогою класу DiGraph. У прикладі показані операції з орієнтованими графами і розповсюджені алгоритми на графах (http://networkx.github.io/documentation/stable/reference/algorithms/index.html).
|
import networkx as nx |
suc [2, 3]
pre []
nei [2, 3]
out [(1, 2), (1, 3)]
in []
2
1.0
1.0
True
True
True
True
[]
[]
Рисунок 45 – Візуалізація орієнтованого графа
True
No cycle found
[(1, 2), (1, 3), (3, 4)]
[(1, 2), (1, 3), (3, 4)]
{1: {1: [1], 2: [1, 2], 3: [1, 3], 4: [1, 3, 4]}, 2:
{2: [2]}, 3: {3: [3], 4: [3, 4]}, 4: {4: [4]}}
[1, 3, 4]
[1, 3, 4]
PageRank {1: 0.16116025883844023, 2:
0.23368249652134615, 3: 0.23368249652134615, 4: 0.3714747481188674}
HITS ({1: 0.9999999990686774, 2: 0.0, 3:
9.313225737481168e-10, 4: 0.0}, {1: 0.0, 2: 0.4999999990686774,
3: 0.4999999990686774, 4: 1.86264514576151e-09})
pyDatalog – логічне програмування в Python
Логічне програмування основане на виведенні нових фактів з існуючих відповідно правил логічного виведення. pyDatalog 0.17.1 (http://sites.google.com/site/pydatalog) – пакет, який додає парадигму логічного програмуавання в Python. Datalog – повністю декларативна підмножина мови логічного програмування Prolog. У декларативному програмуванні програма описує що потрібно досягти, а в імперативному – як. Програма мовою Datalog містить факти, правила логічного виведення і запити. Наприклад, фактом є твердження “Іван є батьком Петра”, правило логічного виведення – “якщо Y батько X, то X дитина Y”, а запит – “знайти усіх дітей Петра”.
|
from __future__ import unicode_literals |
[(u'Ivan',)]
[(u'Petro',), (u'Stepan',)]
[(u'Petro', u'Stepan'), (u'Stepan', u'Petro')]
[(u'Ivan', 2)]
[((1, 2, -3), 4)]
[(0, 1, 1), (1, 0, 1), (0, 0, 0)]
[(u'Ivan', 2)]
[(u'Ivan', 3)]
Зв’язок з інтерпретатором Prolog
В прикладі показано спосіб взаємодії Python програми з інтерпретатором Prolog (SWI-Prolog) за допомогою subprocess.Popen. Більш тісний зв’язок з SWI-Prolog реалізує пакет PySwip (http://github.com/yuce/pyswip).
|
from subprocess import Popen, PIPE,
STDOUT |
('\r\nX = "Petro".\r\n\r\n\r\n', None)
kanren – логічне програмування в Python
kanren 0.2.3 (https://github.com/logpy/logpy) – це реалізація вбудованої предметно-орієнтованої мови логічного програмування miniKanren (http://minikanren.org) [3]. miniKanren спроектована для легкої модифікації і розширення для різних видів логічного програмування. kanren використовує бібліотеку unification для уніфікації – розширеної форми зіставлення з взірцем. Типи, які можуть бути уніфіковані, можуть застосовуватись також для логічного програмування. Наступний код знаходить значення x:
>>> from
unification import *
>>> x = var('x')
>>> unify((1,x,3), (1,2,3))
{~x: 2}
Де (1,x,3), (1,2,3) – два терми (дерево, листки якого є константами або змінними), x – логічна змінна, {~x: 2} – підстановка, unify – функція, яка повертає підстановку за двома термами.
Ціль – це функція з підстановки в потік підстановок:
>>>
goal=eq((1,x,3), (1,2,3))
>>> for s in goal({}):
... print s
{~x: 2}
Ціль створюється за допомогою конструктора цілі (eq, membero, conde та інших). Логічна програма виконується функцією run(n, x, *goals), де n – кількість розв’язків, x – змінна, *goals – послідовність цілей.
|
from kanren import * |
Петро Василь
Василь Петро
Іван
Марія
python-constraint – задачі виконання обмежень
python-constraint 1.3.1 (http://pypi.org/project/python-constraint) – модуль для розв’язування задач виконання обмежень, ціллю яких є знаходження значень змінних, які відповідають заданим обмеженням. Щоб сформулювати таку задачу потрібно визначити змінні, множину їхніх значень і обмеження. Модуль може бути використаний для програмування в обмеженнях, яке є видом декларативного програмування. У модулі доступні такі види обмежень: FunctionConstraint, AllDifferentConstraint, AllEqualConstraint, ExactSumConstraint, MaxSumConstraint, MinSumConstraint, InSetConstraint, NotInSetConstraint, SomeInSetConstraint, SomeNotInSetConstraint.
|
from constraint import * |
[{'a': 3, 'b': 4}, {'a': 3, 'b': 2}, {'a': 3, 'b': 1}, {'a': 2, 'b':
4}, {'a': 2, 'b': 2}, {'a': 2, 'b': 1}, {'a': 1, 'b': 4}, {'a': 1, 'b': 2},
{'a': 1, 'b': 1}]
[{'a': 3, 'b': 4}, {'a': 3, 'b': 2}, {'a': 3, 'b': 1},
{'a': 2, 'b': 4}, {'a': 2, 'b': 2}, {'a': 1, 'b': 4}]
PIL (Pillow) – робота з растровою графікою
Pillow 4.2.1 (Python Imaging Library) – це бібліотека для роботи з растровою графікою (http://pillow.readthedocs.io) [15, 49]. Підтримує велику кількість форматів, їхню конвертацію, різні операції із зображенням.
|
from PIL import Image, ImageDraw, ImageFont,
ImageFilter |
![]()
Рисунок 46 – Растровий рисунок
PyOpenGL – прив’язка до OpenGL
OpenGL – це незалежний від мови програмування і платформи API для рендерингу 2D і 3D векторної графіки. Найчастіше використовується з графічним процесором у програмах для візуалізації, САПР, іграх. PyOpenGL 3.1.0 (http://pyopengl.sourceforge.net) – це прив’язка Python до OpenGL v1.1-4.4, яка створена за допомогою ctypes [40]. Підтримує багато GUI-бібліотек та пов’язаних з OpenGL бібліотек (GLES, GLU, EGL, WGL, GLX, FreeGLUT, GLE). FreeGLUT (http://freeglut.sourceforge.net) – це бібліотека, яка призначена для таких системних задач, як створення вікон, ініціалізація контексту OpenGL і обробка подій. Для роботи програми знадобиться freeglut 3.0.0 MSVC Package (http://www.transmissionzero.co.uk/software/freeglut-devel). Для вивчення PyOpenGL може бути використана офіційна документація (http://www.opengl.org/sdk/docs/man2) та (http://freeglut.sourceforge.net/docs/api.php). Існує також інша прив’язка до OpenGL, яка є частиною pyglet.
|
from OpenGL.GLUT import * |
Рисунок 47 – Вікно програми
pyglet – кросплатформна віконна і мультимедійна бібліотека
pyglet 1.3.2 (http://bitbucket.org/pyglet/pyglet) – це віконна і мультимедійна бібліотека, яка призначена для розробки ігор та інших візуально багатих програм [40]. Підтримує обробку вікон, обробку подій GUI, графіку OpenGL, завантаження зображень і відео, а також відтворення звуків и музики. Працює на Windows, OS X і Linux. У прикладі показано простий переглядач 3D об’єктів OpenGL на основі pyglet.
|
import pyglet |
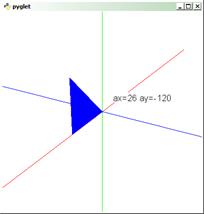
Рисунок 48 – Вікно програми
pythonOCC – прив’язка до геометричного ядра Open CASCADE Technology
Open CASCADE Technology (OCCT) – вільна бібліотека мовою С++ для геометричного моделювання (геометричне ядро), яка найчастіше використовується для створення САПР. Геометричні моделі створюються способом граничного подання BREP (boundary representation) у вигляді топологічних форм (вершин, ребер, циклів, граней, поверхонь, твердотільних форм і їх поєднань). pythonOCC 0.18.1 (http://www.pythonocc.org) – бібліотека Python, що дозволяє використання класів OCCT [34]. Побудована за допомогою SWIG – інструмента для пов’язування коду С++ та Python.
|
from math import pi |
Рисунок 49 – Результати виконання програми
FreeCAD – вільна САПР з Python API
FreeCAD 0.17 (http://www.freecadweb.org) – це вільна параметрична 3D САПР, яка базується на геометричному ядрі Open CASCADE Technology 7.2.0 і володіє Python API. Геометричні моделі створюються способом граничного подання BREP за допомогою її Python-модуля Part, який є прямим зв’язком з OCCT [34]. Повністю OCCT доступна з PythonOCC, але використання FreeCAD модуля Part набагато зручніше. Для виконання прикладу введіть у консолі:
"e:\FreeCAD 0.17x64\bin\python.exe" main.py
Для виконання з довільного інтерпретатора Python27x64 введіть у консолі:
c:\Python27\python.exe main.py
|
import sys |
Compound
389.596349447
0.0
<Face object at 0000000003AF38D0>
<Edge object at 0000000003AF4350>
<type 'Part.Line'>
-1.27414669346
Рисунок 50 – Результати виконання програми
Abaqus/CAE – моделювання методом скінченних елементів
Abaqus/CAE 6.14 (http://www.3ds.com/products-services/simulia) – комерційне середовище для розв’язування задач механіки деформівного твердого тіла, гідрогазодинаміки і електродинаміки методом скінченних елементів (МСЕ). Володіє зручним API мовою Python 2.7, який дозволяє створювати прикладні програми. У прикладі створюється осесиметрична модель деталі, яка розтягується осьовим навантаженням. Зазвичай послідовність розв’язування задач МСЕ містить етапи: створення геометрії, властивостей матеріалу, генерація сітки елементів, створення граничних умов, розв’язування рівнянь і аналіз результатів.
|
from abaqus import * |
7578833.5
[ 0.00022752 0.00070781]
Рисунок 51 – Еквівалентні напруження за критерієм Мізеса-Губера (Па)
SymPy – символьна математика
SymPy (http://www.sympy.org) – це бібліотека для символьної математики, яка призначена для роботи з математичними виразами в аналітичній (символьній) формі на відміну від чисельних обчислень в SciPy [14, 25, 31]. Її можна розглядати як вільну альтернативу системам символьної математики Maple, Mathcad, Mathematica. Для прикладу SymPy дозволяє інтегрувати, диференціювати, спрощувати вирази, розв’язувати рівняння у символьній формі.
|
from sympy import * |
2*x + 2
Add(Mul(Integer(2), Symbol('x')), Symbol('y'))
(y, 2*x)
set([2, x, y])
set([x, y])
12.0000000000000
x**2 - 1/2
0.0998334166468
/
|
| ___
| / 1
| / - dx
| \/ x
|
/
\int \sqrt{\frac{1}{x}}\, dx
<apply><int/><bvar><ci>x</ci></bvar><apply><root/><apply><power/><ci>x</ci><cn>-1</cn></apply></apply></apply>
1
x**2 + 2*x + 1
2*x
2
cos(x)
d / 2\
--\x /
dx
2*x
(x**2*y**2 + 4*x*y + 2)*exp(x*y)
-cos(x)
1
pi
1
x - x**3/6 + x**5/120 - x**7/5040 + O(x**8)
[-2, 2]
[{x: 0, y: 0}]
Eq(z, sqrt(2) + 2)
Eq(f(x), (C1 + C2*x)*exp(x))
Взаємодія з Maple
Maple (http://www.maplesoft.com) – система комп’ютерної математики з можливостями символьних обчислень. У прикладі показано спосіб взаємодії Python з Maple шляхом створення файлу mymaple.mpl з командами Maple та командного файлу mymaple.bat, який створює процес cmaple.exe, що виконує ці команди і повертає файл результатів result.txt.
|
import os |
OMPython – інтерфейс OpenModelica Python
Modelica – це основана на рівняннях об’єктно-орієнтована мова для зручного моделювання складних фізичних систем, які містять, наприклад, механічні, електричні, гідравлічні, термічні субкомпоненти. OpenModelica 1.12 (http://www.openmodelica.org/) – це вільне середовище симуляції мовою Modelica. OMPython – це інтерфейс з OpenModelica мовою Python, який забезпечує доступ до OpenModelica API. Для його інсталяції введіть у консолі:
cd e:\OpenModelica\share\omc\scripts\PythonInterface
c:\Python27\python.exe -m pip install .
В прикладі розв’язується просте
диференціальне рівняння з початковою умовою ![]() :
:
![]() .
.
|
code='''model Simple |
7.38908993012
{'a': 1.0}
(array([0., 0.002, 0.004, ..., 1.998, 2., 2.]),
array([1., 1.00400801, 1.0080321, ..., 54.38076352, 54.59872293, 54.59872293]))
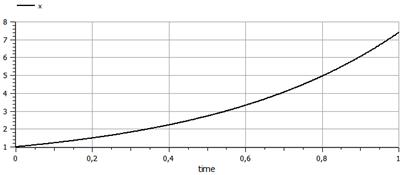
Рисунок 52 – Результати симуляції
xlwt – створення електронних таблиць Excel
xlwt (http://pypi.org/project/xlwt) – бібліотека для створення електронних таблиць у форматі Microsoft Excel 95-2003 на будь-якій платформі. У прикладі за допомогою xlwt 1.3.0 створюється робоча книга і лист Excel, в комірки якого заноситься значення і формула.
|
import xlwt |
pywin32 – інтерфейс до win32 GUI API
Python for Win32 Extensions (pywin32) -це бібліотека, яка забезпечує доступ до багатьох Windows API з мови Python (http://github.com/mhammond/pywin32) [60]. Після установки документація доступна у файлі PyWin32.chm.
Приклад показує можливість застосування pywin32 (версія 221) для управління графічним інтерфейсом інших програм. Програма створює процес calc.exe, знаходить вікно програми і імітує натискання клавіш клавіатури і миші користувачем. Після цього програма входить в цикл, в якому показує відносні координати миші. Щоб завершити програму посуньте курсор миші в верхній лівий кут екрану.
|
import os, sys, time, win32api,
win32gui, win32con |
305 68
295 71
win32com.client – об’єкти Excel
COM (Component Object Model) — платформа компонентно-орієнтованого програмування, яка використовується в ОС Windows. Підтримує повторене використання і можливість взаємодії об’єктів незалежно від мови програмування, на якій вони були розроблені. Основними елементами COM є: об’єкт COM (екземпляр класу COM у сервері COM), сервер COM (програма, яка організовує доступ до створеного в ній об’єкта COM, реалізуючи інтерфейси), клієнт COM (програма, яка, використовуючи інтерфейс, отримує доступ до об’єкта COM), інтерфейс COM (визначає відкриті методи, які використовуються для доступу до об’єкта COM), клас COM (реалізація інтерфейсу COM у сервері COM). Пакет win32com є частиною бібліотеки pywin32 і реалізує пітримку COM у Python [60]. У прикладі створюється клієнт COM для доступу до об’єктів Excel.
|
import win32com.client # імпортувати модуль
win32com.client |

Рисунок 53 – Результат роботи програми в Excel
win32com.client – об’єкти Excel з обробкою подій
В більш складному прикладі створюється клієнт COM для доступу до об’єктів Excel з обробкою подій. Під час оброблення події програми OnSheetBeforeDoubleClick та події робочого листа OnSelectionChange виводиться інформація про вибрані комірки. Цей модуль слід виконувати так:
python main.py
Для виходу слід у консолі натиснути Esc. Дивись інші приклади в c:\Python27\Lib\site-packages\win32com\test.
|
import win32com.client |
SheetBeforeDoubleClick
$A$1
1
1
['Activate', 'AddComment', 'AdvancedFilter']
$A$2
101.0
Рисунок 54 – Робочий лист Excel
win32com.client – об'єкти SOLIDWORKS
В прикладі створюється клієнт COM для доступу до об’єктів системи автоматизованого проектування SOLIDWORKS. Програма змінює значення розміру активної моделі і перебудовує модель.
|
import win32com.client |
pyserial – доступ до послідовного порту
pyserial (http://github.com/pyserial/pyserial) – модуль Python для доступу до послідовного порту на Windows, OSX, Linux, BSD (будь-які POSIX системи) і IronPython [56]. Для тестування віртуальних послідовних портів можна використовувати Eltima Virtual Serial Port Driver (http://www.eltima.com/ru/products/vspdxp) або com0com (http://com0com.sourceforge.net) і створити з’єднані віртуальні порти COM6-COM7. За допомогою Serial Port Terminal можна відкрити COM6 або COM7 для запису чи читання даних. Або можна записувати і читати за допомогою pyserial 2.7, як це показано в прикладі.
|
import serial,time |
COM6
COM7
h e l l o !
pyFirmata – комунікація комп’ютера та Arduino
Arduino (www.arduino.cc) – відкрита і зручна у використанні платформа, яка основана на одноплатному мікроконтроллері Atmel AVR і використовується аматорами для побудови простих систем автоматики і робототехніки [13]. Firmata (http://firmata.org) це загальний протокол для зв’язку мікроконтроллерів із головним комп’ютером. Firmata дозволяє експериментувати з Arduino без необхідності його перепрограмовування кожного разу. У прикладі використано плату Arduino UNO для вимірювання значень температури за допомогою терморезистора і виведення їх на графік у реальному часі.
Передусім установіть драйвер USB-SERIAL для Arduino. У цьому прикладі це CH340 (http://www.wch.cn/download/CH341SER_ZIP.html). Розпакуйте на комп’ютер середовище Arduino IDE. У файлі /avr/boards.txt перевірте швидкість передачі даних uno.upload.speed=57600. Під’єднайте датчик температури (терморезистор) до контактів GND, ANALOG IN 0 (A0), 5V (рис.). Під’єднайте світлодіод до контактів GND і DIGITAL 13. Під’єднайте Arduino до USB-порту комп’ютера. У гілці “порти” диспетчера пристроїв знайдіть USB-SERIAL CH340 (COM9), де COM9 – назва послідовного порту. У вас номер може бути інший. З Arduino IDE завантажте в пам’ять мікроконтроллера приклад Firmata/StandardFirmata. Установіть на комп’ютері pyFirmata (https://github.com/tino/pyFirmata) і запустіть наступний приклад.
Рисунок 55 – Під’єднання датчика температури
|
import matplotlib.pyplot as plt |
Рисунок 56 – Графік температури
concurrent.futures – запуск паралельних задач
concurrent.futures – високорівневий інтерфейс для асинхронного виконання виконуваних об’єктів за допомогою потоків (ThreadPoolExecutor) або процесів (ProcessPoolExecutor). Входить у стандартну бібліотеку Python 3.2, але доступний і для Python 2.7 (http://pypi.org/project/futures). Подібний приклад можна також розробити за допомогою multiprocessing. Див. також приклад використання інтерфейсу futures в розподілених обчисленнях (Dask.Distributed).
|
import concurrent.futures, time |
1 2 3 4
Dask – розподілені обчислення на чистій Python
Dask 0.18.2 (http://dask.pydata.org) – це гнучка бібліотека для паралельних обчислень. Dask забезпечує динамічне планування задач, оптимізоване для інтерактивних обчислювальних навантажень, та прості шляхи масштабування задач Pandas, Scikit-Learn і Numpy. Дозволяє легко паралелізувати довільний Python-алгоритм шляхом створення “лінивих” функцій з відкладеним виконанням. Функція dask.delayed обгортає довільну функцію так, що вона не виконується миттєво, а створює граф задач. Передача відкладених результатів іншим відкладеним функціям створює залежності між задачами. Обчислити результати паралельно можна за допомогою методу compute. Нижче наведено приклад алгоритму, який паралелізується. Для виконання прикладу на кластері див. приклад Dask.Distributed.
|
from dask.distributed import Client |
10
Dask.Distributed – розподілені обчислення
Розподілені обчислення – це вид паралельних обчислень за допомогою множини комп’ютерів, які об’єднані в мережу. Dask.Distributed (http://distributed.readthedocs.io) – це легка бібліотека для розподілених обчислень на Python. Вона розширює API concurrent.futures і Dask (бібліотека паралельних обчислень на чистій Python) для невеликих кластерів. Для виконання прикладу необхідно установити Dask повністю на кожній Windows машині:
pip install "dask[complete]"
Або на Linux-машині:
sudo pip2 install "dask[complete]"
На одній машині (наприклад 192.168.1.33) запустити планувальник:
dask-scheduler
На кожній машині запустити виконавців, які виконують завдання планувальника за допомогою ThreadPool. Якщо обчислення вивільняють GIL (наприклад NumPy або Pandas), введіть:
dask-worker 192.168.1.33:8786
Або, якщо обчислення не вивільняють GIL:
dask-worker 192.168.1.33:8786 --nprocs 4 --nthreads 1
Виконати програму клієнта:
python main.py
Переглянути статус виконання можна в браузері (потрібен установлений Bokeh):
http://192.168.1.33:8787
|
from dask.distributed import Client, as_completed |
<Client: scheduler='tcp://192.168.1.33:8786' processes=8
cores=8>
1, 2, 3, 4
PyQt4 – фреймворк Qt в Python
PyQt4 (http://www.riverbankcomputing.com /software /pyqt) – це “прив’язка” фреймворку Qt до мови Python [45]. Qt – це багатоплатформовий програмний фреймворк для створення ПЗ мовою C++. Містить класи для створення GUI, роботи з мережею, базами даних, OpenGL, мультимедіа і т.д. Існує також прив’язка з більш вільними умовами ліцензування PySide (http://wiki.qt.io/PySide), яка сумісна на рівні API з PyQt. У прикладі показано програму з GUI для розрахунку квадрату числа. Цей приклад буте також працювати в PySide 1.2.4, якщо замінити рядок PyQt4 на PySide.
|
import sys |
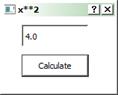
Рисунок 57 – Вікно програми
PyQt4 – елементи керування QtGui
Більш складний приклад використання таких елементів керування як QMainWindow (головне вікно), QMenuBar (смуга меню), QMenu (меню), QAction (дія GUI), QTextBrowser (текстовий браузер), QComboBox (список), QDial (пристрій регулювання), QCheckBox (прапорець), QPixmap (рисунок), QLabel (надпис або рисунок), QTreeWidget (дерево), QTreeWidgetItem (елемент дерева), QFileDialog (вікно вибору файлу), QMessageBox (вікно з повідомленням), QApplication (GUI-застосування). Програма Qt Designer дозволяє полегшити створення складних GUI в режимі WYSIWYG. Після створення нею файлу опису GUI main.ui потрібно згенерувати код Python за допомогою програми pyuic:
pyuic.py -x main.ui -o main.py
|
import sys |
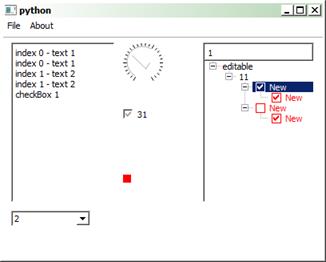
Рисунок 58 – Вікно програми
PyQt4 – створення елемента керування
В прикладі показано створення нового елемента керування (GUI-віджету) MyButton шляхом успадкування класу QPushButton (кнопка). На відміну від базового класу нова кнопка володіє атрибутом state, логічне значення якого змінюється на протилежне під час натиску на неї. Крім того це значення відображається на самій кнопці.
|
import sys |

Рисунок 59 – Вікно програми
PyParsing – зручний синтаксичний аналіз
Синтаксичний аналіз (парсинг) – це процес зіставлення послідовності лексем (неподільних груп символів) певної мови з її формальною граматикою (способом опису мови). Лексеми отримуються шляхом лексичного аналізу (токенізації). PyPasing 2.2.0 (http://pypi.org/project/pyparsing) – модуль для синтаксичного аналізу, який реалізує альтернативний і більш зручний підхід для створення і використання граматик, у порівнянні з традиційним lex/yacc або використанням регулярних виразів. Модуль містить класи для створення граматик прямо в Python-коді.
|
from __future__ import print_function |
pymorphy2 – морфологічний аналізатор
pymorphy2 (https://github.com/kmike/pymorphy2) – морфологічний аналізатор для російської і української мови. Повертає граматичну інформацію про слово (число, рід, відмінок, частина мови і т.д.), приводить слово до нормальної форми, ставить слово в потрібну форму. Використовує словник opencorpora.org. Для незнайомих слів будуються гіпотези. Дивись також NLTK (www.nltk.org) – пакет для обробки природної мови. Ці пакети широко застосувуються у галузі штучного інтелекту.
|
import pymorphy2 |
INFN
уменьшить
уменьшит
уменьшить уменьшил уменьшила уменьшило ...
pygments – підсвітка синтаксису
Підсвітка синтаксису – це виділення синтаксичних конструкцій тексту за допомогою різних шрифтів, їхніх кольорів і написань. Використовується для спрощення сприйняття тексту. Підсвітка синтаксису виконується за допомогою лексичного аналізатора, який визначає окремі лексеми (послідовність символів, що має певне значення). Пакет pygments 2.2.0 (http://pygments.org) призначений для підсвічування синтаксису, підтримує близько 300 мов, дозволяє створювати нові лексичні аналізатори, виводить у багатьох форматах (HTML, RTF, LaTeX та ін.), може використовуватись у командному рядку або як бібліотека.
|
from pygments import highlight # повертає відформатований
текст |
<div class="highlight"><pre><span></span><span class="k">print</span> <span class="s2">"Hello World"</span> <span class="c1"># коментар</span>
</pre></div>
<div class="highlight"><pre><span></span>print "Hello World" <span class="c"># коментар</span>
</pre></div>
pygments – підсвітка синтаксису в Tkinter
Приклад показує способи підсвітки синтаксису в текстовому віджеті Tkinter.Text за допомогою пакету pygments.
|
from Tkinter import * |
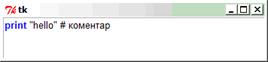
Рисунок 60 – Вікно програми
lxml – простий і швидкий парсинг XML і HTML
lxml 4.1.0 (http://lxml.de) – це Python-бібліотека для обробки XML і HTML, яка є прив’язкою до C бібліотек libxml2 і libxslt. Володіє повною підтримкою XML, є швидкою і зручною у використанні, сумісна з ElementTree API. У прикладі розглядається використання HTMLParser та xpath для отримання ключових слів некоректного HTML документу з тегу meta. XPath (XML Path Language) – це мова запитів до елементів XML документа.
|
from StringIO import StringIO |
Python, XML
Python, XML
lxml – XSLT трансформації
XSLT (eXtensible Stylesheet Language Transformations) – це мова перетворення XML-документів. У прикладі за допомогою lxml до початкового документа XML застосовується таблиця стилів XSLT і отримується перетворений документ XML. Правила вибору даних із початкового документу створюються мовою запитів XPath.
|
from lxml import etree |
<?xml version="1.0"?>
<foo>Text</foo>
Bottle – легкий WSGI веб-фреймворк
Bottle (http://bottlepy.org) – це швидкий, простий і легкий WSGI мікро веб-фреймворк для Python [39]. Він розповсюджується як один файловий модуль і не має ніяких залежностей крім стандартної бібліотеки Python. Містить вбудований сервер і підтримує інші високопродуктивні WSGI сервери. У прикладі використано стару версію Bottle 0.5.8, яка працює навіть на PythonCE. Для тестування прикладу запустіть модуль і введіть в адресному рядку браузера один з URL, наведених нижче. Також ознайомтесь з подібним пакетом Flask [30].
|
from bottle import route, run, request,
send_file, WSGIRefServer |
127.0.0.1 - - [02/Aug/2018 14:28:48] "GET / HTTP/1.1" 200 21
127.0.0.1 - - [02/Aug/2018 14:29:06] "GET /index.html HTTP/1.1" 200 21
127.0.0.1 - - [02/Aug/2018 14:29:20] "GET /hello/John HTTP/1.1" 200 11
127.0.0.1 - - [02/Aug/2018 14:29:33] "GET /hello?name=John HTTP/1.1" 200 11
127.0.0.1 - - [02/Aug/2018 14:30:12] "GET /form HTTP/1.1" 200 222
127.0.0.1 - - [02/Aug/2018 14:30:42] "POST /edit HTTP/1.1" 200 11
127.0.0.1 - - [02/Aug/2018 14:31:11] "GET /static.html HTTP/1.1" 200 77
127.0.0.1 - - [02/Aug/2018 14:31:11] "GET /pic.png HTTP/1.1" 200 75
Рисунок 61 – HTML-форма в браузері
Розділ 3. Задачі
1. Створити програму для обчислення значення функції f(x), якщо i=1 (рис.). Значення аргументу в програму передається з командного рядка.
![]()
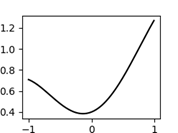
Рисунок 62 – Графік функції f(x)
2. Створити програму для обчислення значення функції g(x), якщо a=-0,5; b=0,5.
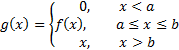
3. Розв’язати попередню задачу з використанням підпрограми-функції, яка повертає значення g(x).
4. Створити програму для виведення списку значень функції g(x), якщо x змінюється від -1 до 1 з кроком 0,1. Використати оператори циклу for або while.
5. Знайти
наближене значення інтеграла ![]() з кроком інтегрування
0,1. Використати оператори циклу for або while.
з кроком інтегрування
0,1. Використати оператори циклу for або while.
6. Визначте тривалість обчислення значення функції f(x) і її інтеграла на вашому комп’ютері.
7. Знайти наближене мінімальне і максимальне значення функції f(x) на проміжку [-1, 1], якщо крок x рівний 0,1. Використати оператори циклу і умови.
8. Знайти наближено корінь рівняння f(x)=1 на проміжку [-1,1], якщо крок x рівний 0,1. Використати оператори циклу і умови.
9. Розв’язати попередні задачі з використанням списків і функцій sum, min, max, sorted. Вивести списки, їхнє перше і останнє значення, довжини списків. Знайти значення аргумента argmin та argmax.
10. Створити словник, ключами якого є елементи кортежа (-1, 0, 1), а значеннями – відповідні значення функції f(x). Вивести усі ключі і значення.
11. Створити довільний рядок. За допомогою операторів циклу і умови замінити задані символи (або слова) в рядку на інші. Розв’язати цю ж задачу за допомогою методу replace.
12. Створити довільний рядок. За допомогою операторів циклу і умови замінити текст у дужках на три крапки (...). Розв’язати цю ж задачу за допомогою модуля re.
13. Дано множини A={1,2,3,4} і B={3,4,5,6}. Знайти об’єднання, перетин, різницю і симетричну різницю цих множин.
14. Створити рекурсивну функцію f(x,n), де n – додатне ціле число:
![]()
15. Створити
генератор для утворення послідовності ![]() .
.
16. Записати у текстовий файл значення аргументу x і функції f(x), якщо x змінюється від -1 до 1 з кроком 0,1. Виконати пошук у створеному файлі значення f(0).
17. Розв’язати попередню задачу з використанням модуля csv.
18. За допомогою модуля pickle записати у бінарний файл списки значень аргументу x і функції f(x). Виконати пошук у створеному файлі значення f(0).
19. Створити клас, який містить коструктор, атрибути-дані xmin, xmax, dx і атрибути-методи f(x), X(), F(), які, відповідно, повертають значення функції, список значень аргумента x, список значень функції f(x). Створити об’єкти класу.
20.
Створити клас шляхом успадкування класу з попередньої задачі, який додатково
містить методи, що повертають значення похідної ![]() і інтеграла
і інтеграла 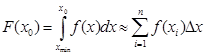 в заданій точці
в заданій точці ![]() , де
, де ![]() .
.
21. Створити модуль і пакет з класом із попередньої задачі. Імпортувати модуль і створити об’єкти класу.
22.
Створити клас, який описує поняття вектора ![]() і містить функції для обчислення його довжини
і містить функції для обчислення його довжини
![]() , додавання двох векторів
, додавання двох векторів ![]() (перевантажити __add__),
скалярного множення
(перевантажити __add__),
скалярного множення ![]() (перевантажити __mul__) і
векторного множення:
(перевантажити __mul__) і
векторного множення:
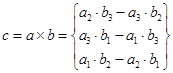 .
.
23. Розв’язати попередню задачу шляхом створення класу-контейнера.
24. Дослідити структуру довільного класу і об’єктів за допомогою функцій type(), dir(), vars(), getattr(), методів __sizeof__(), __subclasses__(), атрибутів __dict__, __doc__, __bases__ та модуля inspect.
25. Створити і використати декоратор, що повертає похідну функції f(x) заданого порядку. Підказка: для першого порядку декоратор повинен повертати нову функцію f_=lambda x: (f(x+0.001)-f(x))/0.001.
26. Обчислити декартів добуток множин {1,2,3}, {4,5,6} з використанням оператора for. Перевірити результат функцією product модуля itertools.
27. За допомогою функцій модуля itertools отримати усі можливі комбінації і розміщення елементів множини {1, 2, 3} по 2 елементи.
28. Від дати 2019-01-02 02:17:01 відняли 1e6 секунд. Яка це дата? Який це день тижня?
29. Дано рядок, який містить підрядки <ключ>=<значення>. Зберегти усі ключі і значення у базу даних. Прочитати з бази даних значення за заданим ключем. Використати модулі anydbm або sqlite3.
30. Зберегти у текстовий файл список елементів поточного каталогу і вкладених каталогів. Створити zip-архів із цим файлом і tar-архів із поточним каталогом. Визначити розмір цих архівів у байтах. Створити новий каталог і скопіювати в нього ці файли.
31. Розв’язати задачу про пошук мінімуму/максимуму функції шляхом поділу області пошуку на дві частини і розпаралелювання пошуку на два процеси. Використати модуль subprocess.
32. Розв’язати попередню задачу шляхом використання модуля multiprocessing.
33. Розв’язати попередню задачу шляхом використання concurrent.futures.
34. Розв’язати попередню задачу шляхом використання dask.
35. Розв’язати попередню задачу шляхом виконання одного процесу на локальній машині, а другого – на віддаленій. Використати модуль socket або SocketServer.
36. Розв’язати попередню задачу шляхом використання dask.distributed.
37. Розробити веб-програму для обчислення значення функції f(x). Використати CGIHTTPServer.
38. Розробити веб-програму для обчислення значення функції f(x). Використати стандартну wsgiref.simple_server або bottle.
39. Створити програму, яка отримує дані від веб-сервера (дивись попередні задачі). Використати модулі urllib2 та HTMLParser.
40. Створити програму, яка записує значення функції f(x) у XML-документ у такому вигляді: <point><x>0.1</x><y>-1.25</y></point>. Використати xml.dom.minidom.
41. Створити програму, яка шукає в XML-документі з попередньої задачі значення y>0. Використати xml.etree.ElementTree або lxml.
42. Розробити програму з графічним інтерфейсом Tkinter, яка виводить на вікно документ XML з підсвічуванням синтаксису. Використати pygments.
43. Розробити програму з графічним інтерфейсом Tkinter для виведення значення функції f(x). Передбачити обробку виняткових ситуацій, які виникають під час введення недопустимих значень аргументу.
44. Розробити програму з графічним інтерфейсом Tkinter для виведення списку значень функції f(x). Використати такі класи як Button, Label, Entry, Checkbutton, Radiobutton, Listbox.
45. Розробити програму з графічним інтерфейсом PyQt4 або PySide для попередніх задач.
46. Розробити бібліотеку DLL мовою C з функцією, що повертає список значень функції f(x). Викликати цю функцію з модуля Python.
47. Розробити Python-модуль розширення мовою C++, який повертає список значень функції f(x).
48. Створити масив значень функції f(x) за допомогою numpy. Побудувати графік функції за допомогою matplotlib.
49. Розв’язати задачі про пошук коренів рівняння f(x)=1, мінімуму функції f(x) і її інтеграла з використанням функцій numpy.
50. Розв’язати систему лінійних рівнянь за допомогою numpy.linalg:
![]()
51. Згенерувати випадкову вибірку з нормального розподілу (μ=20, σ=2, N=1000). Обчислити емпіричні середнє значення та середньоквадратичне відхилення.
52.
Дано поліном ![]() . За допомогою методів класу numpy.poly1d обчислити значення полінома, його похідної і
первісної в точці x=5.
. За допомогою методів класу numpy.poly1d обчислити значення полінома, його похідної і
первісної в точці x=5.
53. За допомогою scipy-функцій diff та cumtrapz побудувати графіки похідної і первісної функції f(x).
54. За
допомогою scipy обчислити визначений інтеграл ![]() .
.
55.
Розв’язати систему диференціальних рівнянь з
початковими умовами ![]() :
:
![]()
![]()
56. Дано дискретний набір значень x = [0, 1, 2, 3], y = [0, 1, 4, 9]. Обчислити значення y для x=2,5 шляхом лінійної інтерполяції і інтерполяції квадратичним сплайном.
57.
За допомогою scipy.optimize.fsolve
роз’язати рівняння ![]() .
.
58. За допомогою scipy.optimize.root роз’язати систему нелінійних рівнянь
![]()
![]()
59.
За допомогою scipy.optimize.curve_fit знайти регресію виду ![]() за даними x, y (табл.). Знайти
коефіцієнт детермінації
за даними x, y (табл.). Знайти
коефіцієнт детермінації ![]() .
.
Таблиця 2 – Емпіричні дані – залежність y від x
|
x |
0 |
1 |
2 |
3 |
|
y |
0 |
1 |
4 |
10 |
60.
За допомогою scipy.optimize.curve_fit знайти регресію виду ![]() за даними x, y, z
(табл.) Знайти коефіцієнт детермінації
за даними x, y, z
(табл.) Знайти коефіцієнт детермінації ![]() .
.
Таблиця 3 – Емпіричні дані – залежність z від x і y
|
y x |
1 |
2 |
3 |
4 |
|
1 |
0 |
0 |
1 |
4 |
|
2 |
0 |
1 |
4 |
8 |
|
3 |
1 |
4 |
8 |
10 |
|
4 |
4 |
8 |
10 |
20 |
61. Знайти мінімум функції f(x) в межах [-1, 1] за допомогою scipy.optimize. Спробуйте різні методи оптимізації. Визначте тривалість обчислень для кожного методу.
62. Дано випадкову величину з нормальним розподілом (μ=20, σ=2). Знайти імовірність попадання значень в інтервал (15, 25). Знайти квантілі з рівнем 0,1 і 0,9.
63. Дано випадкову величину з нормальним розподілом (μ=20, σ=2). Згенерувати з неї вибірку розміром 100 значень. Візуально порівняти гістограму вибірки і функцію густини цього розподілу.
64. За допомогою дискретного перетворення Фур'є розрахувати спектр частот для сигналу
![]() .
.
65. За результатами попередньої задачі і за допомогою оберненого дискретного перетворення Фур’є отримати відфільтрований сигнал із частотами, які більші 7.
66. Обчислити центроїди двох кластерів за даними:
|
x |
5 |
5 |
4 |
6 |
4 |
4 |
5 |
6 |
6 |
4 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
2 |
2 |
1 |
|
y |
5 |
4 |
3 |
6 |
5 |
4 |
4 |
4 |
5 |
5 |
1 |
0 |
0 |
2 |
1 |
2 |
1 |
1 |
0 |
1 |
67. За допомогою xlwt створити в Excel наступну таблицю:
|
A |
B |
|
1 |
2 |
|
2 |
|
|
3 |
-1 |
|
4 |
3 |
|
5 |
6 |
68. Виконати попередню задачу з використанням win32com.client і Excel.
69. Зберегти попередню таблицю як файл CSV. За допомогою pandas прочитати цей файл і cтворити об’єкт DataFrame. Відкинути рядки з відсутніми даними та з даними B<0. Створити новий стовпчик C з сумою A+B. Конвертувати стовпчики A і B в numpy.ndarray.
70. Дано два класи 0 і 1 з ознаками x і y:
|
x |
5 |
5 |
4 |
6 |
4 |
4 |
5 |
6 |
6 |
4 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
2 |
2 |
1 |
|
y |
5 |
4 |
3 |
6 |
5 |
4 |
4 |
4 |
5 |
5 |
1 |
0 |
0 |
2 |
1 |
2 |
1 |
1 |
0 |
1 |
|
Клас |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
За допомогою scikit-learn визначити клас точки x=5, y=6.
71. Дано граф, заданий вершинами 1, 2, 3, 4 і ребрами (1, 2), (2, 3), (2, 4), (3, 4). Знайти найкоротший шлях між вузлами 1, 4.
72. Дано предикат "причина" та факти "A причина B", "B причина C", "A причина D". Задано правило логічного виведення "якщо X причина Y, то Y наслідок X". Знайти усі наслідки А. Використати pyDatalog або kanren або зв’язок з інтерпретатором Prolog.
73. Дано змінну a з множиною допустимих значень {1, 3, 5, 7, 9} та змінну b з множиною допустимих значень {0, 2, 4, 6, 8}. За допомогою python-constraint знайти усі розв’язки задачі a+b>10.
74. За допомогою PIL відкрити будь-яке зображення, повернути його на 90 градусів вправо і зберегти в відтінках сірого. За допомогою image.getpixel((x,y)) визначити колір центрального пікселя.
75. За допомогою pyOpenGL або pyglet створити тривимірну сцену з трьома кубами, які розташовані рядом і повернуті на різні кути.
76. За допомогою pythonOCC або FreeCAD створити тривимірне тіло шляхом об’єднання призми і сфери. Обчислити об’єм тіла.
77. Створити макрос для Abaqus/CAE для обчислення напружень в осесиметричній моделі циліндричного тіла.
78. Дано вираз ![]() . За
допомогою SymPy виконати підстановку
. За
допомогою SymPy виконати підстановку ![]() , спростити
вираз, отримати похідну і первісну в символьному виді. Обчислити значення
виразу, поxідної та первісної для x=2.
, спростити
вираз, отримати похідну і первісну в символьному виді. Обчислити значення
виразу, поxідної та первісної для x=2.
79. За допомогою SymPy розв’язати в символьному виді рівняння відносно x
![]() .
.
80. За допомогою SymPy розв’язати в символьному виді систему рівнянь відносно x,y
![]() ,
,
![]() .
.
81. За допомогою sympy.dsolve розв’язати систему диференціальних рівнянь (знайти функції x(t), x’(t))
![]()
![]()
82.
За допомогою OMPython та OpenModelica розв’язати попередне рівняння з початковими
умовами ![]() .
.
83. За допомогою win32com.client змінити розміри довільної параметричної моделі SOLIDWORKS і перебудови її.
84. За допомогою pyserial та pickle записати і прочитати довільний Python-об’єкт через віртуальні послідовні порти.
85. За допомогою PyParsing розробити синтаксичний аналізатор G-коду для верстату з числовим програмним керуванням. Обмежитись командами G00 і G01. Наприклад:
G00 X0.0 Y0.0 Z0.0
G01 X0.0 Y1.0 Z0.0
1. Allen B. Downey. Think Complexity. – Needham, Massachusetts : Green Tea Press, 2011. – 146 p.
2. Allen B. Downey. Think Stats, Second Edition. – O’Reilly, 2015. – 255 p.
3. Artificial Intelligence with Python / Prateek Joshi. – Birmingham : Packt, 2017. – 437 p.
4. Ashish Kumar. Learning Predictive Analytics with Python – Packt Publishing, 2016. – 493 p.
5. Doug Hellmann. Python Module of the Week [Electronic resource]. – Mode of access: https://pymotw.com/2/
6. H. Berendsen. A Student’s Guide to Data and Error Analysis. – Cambridge University Press, 2011. – 239 p.
7. H. J. C. Berendsen. Simulating the physical world. Hierarchical Modeling from Quantum Mechanics to Fluid Dynamics. – Cambridge University Press, 2007. – 626 p.
8. Hans Petter Langtangen. A Primer on Scientific Programming with Python. 5th Edition. – Springer, 2016. – 942 p.
9. Jaan Kiusalaas. Numerical Methods in Engineering with Python. – 2ed. – Cambridge University Press, 2010. – 434 p.
10. José Unpingco. Python for Probability, Statistics, and Machine Learning. – Springer, 2016. – 288 p.
11. Landau R. H. Computational Physics. Problem Solving with Python, 3rd completely revised edition / Rubin H. Landau, Manuel J. Páez, Cristian C. Bordeianu. – Weinheim : Wiley-VCH, 2015. – 647 p.
12. Luca Massaron, Alberto Boschetti. Regression Analysis with Python. – Packt Publishing, 2016. – 416 p.
13. Pratik Desai. Python Programming for Arduino. – Birmingham : Packt Publishing, 2015. – 576 p.
14. Scipy Lecture Notes [Electronic resource]. – Mode of access : http://www.scipy-lectures.org/
15. Shane Torbert. Applied Computer Science. Second Edition. – Fairfax : Springer, 2016. – 291 p.
16. Swaroop C. H. A Byte of Python [Электронный ресурс]. Пер. с англ. Режим доступа: http://wombat.org.ua/AByteOfPython
17. Thomas Haslwanter. An Introduction to Statistics with Python: With Applications in the Life Sciences. – Springer, 2016. - 285 p.
18. Андерс М. Написание скриптов для Blender 2.49. Пер. с англ. – PACK, 2010. – 348 c.
19. Бизли Д. Python. Подробный справочник. – Пер. с англ. – СПб. : Символ-Плюс, 2010. – 864 с., ил.
20. Бринк Хенрик. Машинное обучение / Бринк Хенрик, Ричардс Джозеф, Феверолф Марк. - СПб. : Питер, 2017. - 336 с.
21. Буйначев С. К. Основы программирования на языке Python: учебное пособие / С. К. Буйначев, Н. Ю. Боклаг. – Екатеринбург : Изд-во Урал. ун-та, 2014. – 91 c.
22. Буйначев С. К. Применение численных методов в математическом моделировании : учебное пособие / С. К. Буйначев. – Екатеринбург : Издательство Уральского университета, 2014. – 70, [2] c.
23. Бхаргава А. Грокаем алгоритмы. Иллюстрированное пособие для программистов и любопытствующих. – СПб. : Питер, 2017. – 288 с.: ил.
24. Бэрри, Пол. Изучаем программирование на Python / Пол Бэрри; пер. с англ. — Москва : Издательство «Э», 2017. — 624 с. : ил.
25. Вабищевич П. Н. Численные методы: Вычислительный практикум / Петр Николаевич Вабищевич. — М. : Книжный дом «ЛИБРОКОМ», 2010. — 320 с.
26. Васильев А. Н. Python на примерах. Практический курс по программированию. – СПб.: Наука и Техника, 2016. – 432 с.: ил.
27. Гифт Н., Джонс Д. Python в системном администрировании UNIX и Linux – Пер. с англ. – СПб. : Символ-Плюс, 2009. – 512 с., ил.
28. Гойвертс Я., Левитан С. Регулярные выражения. Сборник рецептов, 2-е изд. – СПб. : Символ-Плюс, 2015. – 704 с.
29. Грас Дж. Data Science. Наука о данных с нуля: Пер. с англ. – СПб. : БХВ-Петербург, 2017. – 336 с.: ил.
30. Гринберг М. Разработка веб-приложений с использованием Flask на языке Python. – М. : ДМК Пресс, 2014. – 272 с.
31. Доля П. Г. Введение в научный Python. – Харьков : ХНУ, 2016 – 265 с.
32. Доусон М. Программируем на Python. – СПб. : Питер, 2014. – 416 с.: ил.
33. Карау Х., Конвински Э., Венделл П., Захария М. Изучаем Spark: молниеносный анализ данных. – М. : ДМК Пресс, 2015. – 304 с.: ил.
34. Копей В. Б. Ядро геометричного моделювання Open CASCADE Technology для Python-програмістів: методичні вказівки для самостійної роботи / В. Б. Копей. – Івано-Франківськ : ІФНТУНГ, 2017. – 47 c.
35. Луис Педро Коэльо, Вилли Ричарт. Построение систем машинного обучения нa языке Python 2-е издание / Пер. с англ. Слинкин А. А. – М. : ДМК Пресс, 2016. – 302 с.: ил.
36. Лутц М. Python. Карманный справочник, 5-е изд.: Пер. с англ. – М. : ООО "И.Д.Вильямс", 2015. – 320 с.: ил.
37. Лутц М. Изучаем Python, 4-е издание. – Пер. с англ. – СПб. : Символ-Плюс, 2011. – 1280 с.: ил.
38. Лучано Ромальо. Python. К вершинам мастерства – М. : ДМК Пресс, 2016. – 768 с.
39. Любанович Билл Простой Python. Современный стиль программирования. — СПб. : Питер, 2016. — 480 с.: ил.
40. Марк Саммерфилд. Python на практике. / Пер. с англ. Слинкин А.А. – М. : ДМК Пресс, 2014. – 338 с.: ил.
41. Марманис Х., Бабенко Д. Алгоритмы интеллектуального Интернета. Передовые методики сбора, анализаи обработки данных. – Пер. с англ. – СПб. : Символ-Плюс, 2011. – 480 с., ил.
42. Мэтиз Эрик Изучаем Python. Программирование игр, визуализация данных, вебприложения. — СПб. : Питер, 2017. — 496 с.: ил.
43. Мюллер А. Введение в машинное обучение с помощью Python. Руководство для специалистов по работе с данными / Андреас Мюллер, Сара Гвидо. – Вильямс, 2017. – 480с.
44. Плас Дж. Вандер. Python для сложных задач: наука о данных и машинное обучение. — СПб. : Питер, 2018. — 576 с.: ил
45. Програмування числових методів мовою Python : навч. посіб. / А. Ю. Дорошенко, С. Д. Погорілий, Я. Ю. Дорогий, Є. В. Глушко; за ред. А. В. Анісімова. – К. : Видавничо-поліграфічний центр "Київський університет", 2013. – 463 с.
46. Рашка С. Python и машинное обучение / пер. с англ. А . В . Логунова. – М. : ДМКПресс, 2017. – 418 с.: ил.
47. Рейтц К., Шлюссер Т. Автостопом по Python. — СПб. : Питер, 2017. — 336 с.: ил.
48. Ричардсон, Крэйг. Программируем с Minecraft. Создай свой мир с помощью Python / Крэйг Ричардсон; пер. с англ. — М. : Манн, Иванов и Фербер, 2017. — 368 с.: ил.
49. Свейгарт, Эл. Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих. – М. : Вильямс, 2017. – 592 с.
50. Сегаран Т. Программируем коллективный разум. – Пер. с англ. – СПб. : Символ-Плюс, 2008. – 368 с., ил.
51. Сейтц, Джастин. Программирование на Python для хакеров. - Пер. с англ, 2012. – 208 с.
52. Силен Д. Основы Data Science и Big Data. Python и наука о данных / Силен Дэви, Мейсман Арно, Али Мохамед – СПб. : Питер, 2017. – 336 с.
53. Соловьёв И. А., Червяков А. В., Репин А. Ю. Вычислительная математика на смартфонах, коммуникаторах и ноутбуках с использованием программных сред Python: Учебное пособие. — СПб. : Издательство «Лань», 2011. — 272 с.
54. У. Сэнд, К. Сэнд. Hello World! Занимательное программирование. — СПб. : Питер, 2016. — 400 с.: ил.
55. Уэс Маккинли. Python и анализ данных / Пер. с англ. Слинкин А. А. – М. : ДМК Пресс, 2015. – 482 с.: ил.
56. Федоров Д. Ю. Основы программирования на примере языка Python : учеб.пособие / Д. Ю. Федоров. – СПб., 2016. – 176 с.
57. Шоу, Зед. Легкий способ выучить Python / Зед Шоу; пер. с англ. — Москва : Издательство «Э», 2017. — 352 с.
58. Язык программирования Python. / Г. Россум, Ф. Л. Дж. Дрейк, Д. С. Откидач, М. Задка, М. Левис, С. Монтаро, Э. С. Реймонд, А. М. Кучлинг, М.-А. Лембург, К.-П. Йи, Д. Ксиллаг, Х. Г. Петрилли, Б. А. Варсав, Дж. К. Ахлстром, Дж. Роскинд, Н. Шеменор, С. Мулендер. – 2001. – 454 c.
59. Mohammed Zuhair Al-Taie, Seifedine Kadry. Python for Graph and Network Analysis. – Springer, 2017. – 211 p.
60. Hammond Mark, Robinson Andy. Python Programming on Win32. – O’REILLY. – 2000. – 652 p.